The final month of Ubuntu 16.04 LTS was fast approaching and our Kubernetes clusters were still blissfully running on the soon-to-expire OS. The Platform team at WeTransfer were certain that an upgrade to 20.04 was our next step, but we were less certain about baking new Amazon Machine Images (AMI) on our aging build infrastructure.
For years, baking had happened at WeTransfer on The Packer Machine, an EC2 instance that to this day we're not entirely sure would survive a reboot. The task of baking a new AMI consisted of SSHing into the instance, pulling the latest Packer and Ansible configuration, running a shell script which wrapped Packer and waiting on Ansible to run through its plays and Packer to publish the AMI. To add a little spice to this otherwise mechanical, uninspiring and slow task, we purchased a chef's hat, and donned the hat every time we baked anew.

The novelty of wearing the chef's hat eventually wore off, and our big brains eventually stretched it out to the point of making it unwearable. Alas, The Packer Machine would not disappear with cheap parlor tricks; it had to be engineered into retirement. Luckily, the upgrade to 20.04 presented us with an opportunity to do so. Enter WeBake.
🍞 Enter WeBake
WeBake is the name we've given to our next generation AMI baking solution. And though the OS images that WeBake would produce are undoubtedly lower-level, we wanted WeBake itself to feel much like other modern applications at WeTransfer: one with a Dockerfile and YAML manifests, deployed by our in-house deploy system named WeDeploy and run on Kubernetes. The reality was that the internet was devoid of examples of others doing the same. Nevertheless, we soldiered on with Hashicorp's official Packer image and WeTransfer's standard service onboarding.
The first step to running Packer on Kubernetes was to choose a builder. Packer's EBS builder was easiest to reason about: run Packer, have it launch an EC2 instance, configure its EBS volume, and then publish the AMI. However, breaking out of the container by launching EC2 instances felt slow, wasteful and not very cloud native. On the other hand, the chroot builder was more self-contained, but also a more difficult pill to swallow. Creating a chroot. In a Docker container. On a VM. What could go wrong? And like the EBS builder, it too required a degree of breaking out of a container.
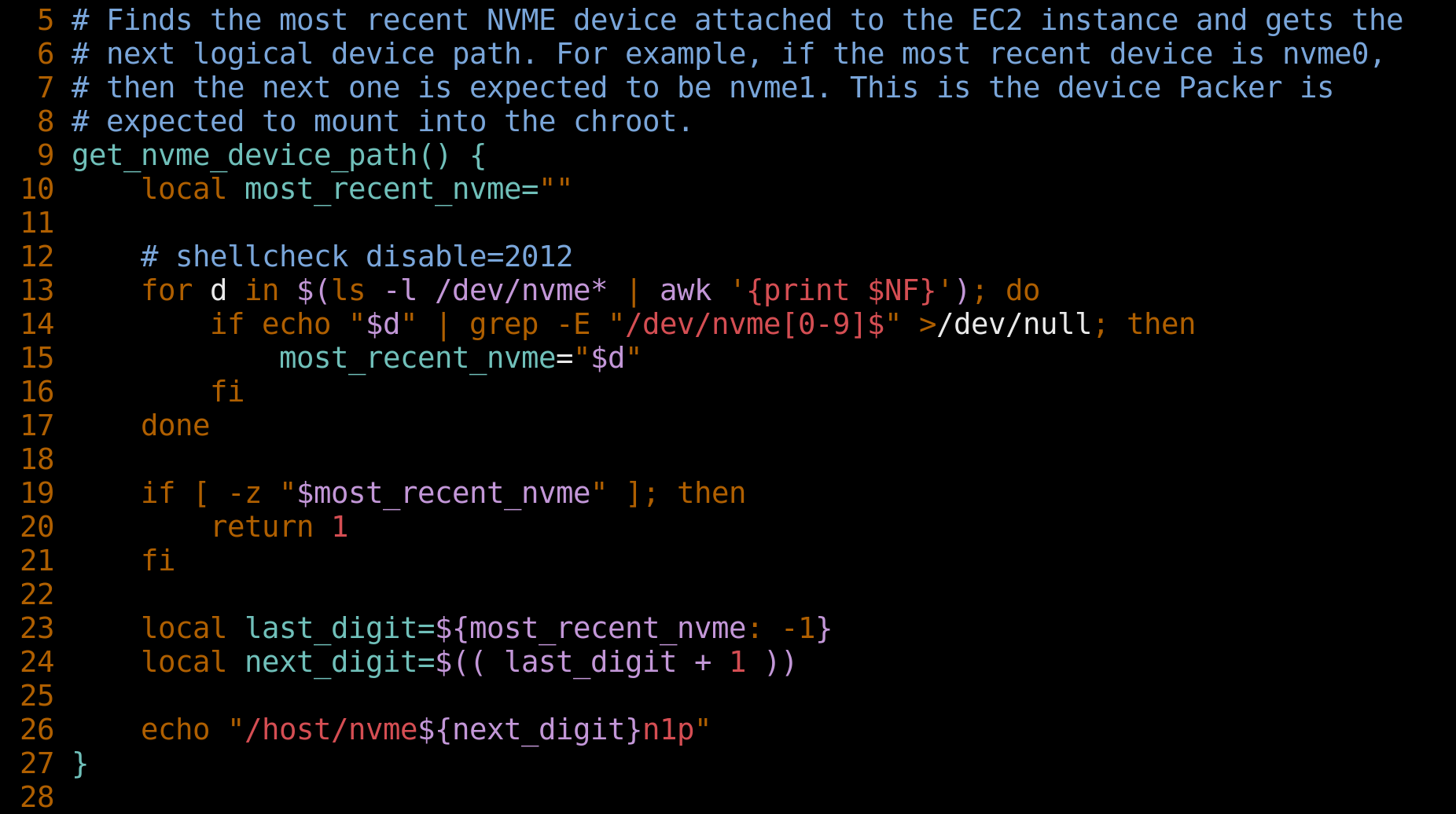
You see, Packer expects to mount an NVMe device in which to create the chroot. In this cloud native world of ours, the path to said device is non-deterministic and is dependent upon how many other NVMe devices existed on the host prior to a WeBake pod being scheduled on it. As a result, devices have to be enumerated on pod startup and the next device in-sequence chosen as the value for the 'nvme_device_path' property (race conditions 🙈).
The inception of Chroot In Docker and the device resolution complexity aside, the chroot builder ultimately proved its worth in speediness, being roughly twice as fast as the EBS builder. And that's the one we chose for WeBake 🚀.
🤲🏻The Oath of AMI Baking
Once we had a skeleton Packer configuration, our efforts focused on porting over the legacy configuration used to provision 16.04 and 18.04 images. The legacy configuration was as you might expect it, a dizzying array of shell scripts, environment variables, Ansible roles and tags, when-conditions, conditions in Jinja template files, you name it! The complexity made it nearly impossible to reason about the contents of an image. Having learned from previous ignorance, we swore an oath not to repeat past mistakes for 20.04.
The Platform team, hereby, solemnly swears to:
Delegate to the ansible-local provisioner as soon as possible.
Using the provisioner is an obvious choice for those already familiar with Ansible. When to have Packer delegate to Ansible is another story. The shell provisioner is all too convenient to run the random, odd command, but using it repeatedly may lead to provisioning configuration that is 1-part Packer and another part Ansible without clear justification. To avoid a "split brain" configuration scenario, we aimed to configure Packer to do the bear minimum with the shell provisioner: 'apt-get update', 'apt-get install ansible', then delegate the rest to Ansible.
Previous versions of our AMIs had been purpose-built per environment and region, and dating back even further, per application. This design choice led to long bake times, package version drift and a very confusing set of Ansible plays. WeBake aimed for reusable environment-agnostic AMIs for our entire fleet. This goal also helped us avoid configuration complexity and forced us to build our services to resolve information about their operating environment at runtime. One example is the way we construct hostnames. At WeTransfer, we like to add helpful hints to hostnames like an environment and a region, e.g. 'kubernetes-prod-euwest1-07a38e448ad62b4da'. Querying the AWS IMDS on boot instead of baking in configuration is a simple way to ensure environment-agnostic images are produced.
Define composable roles.
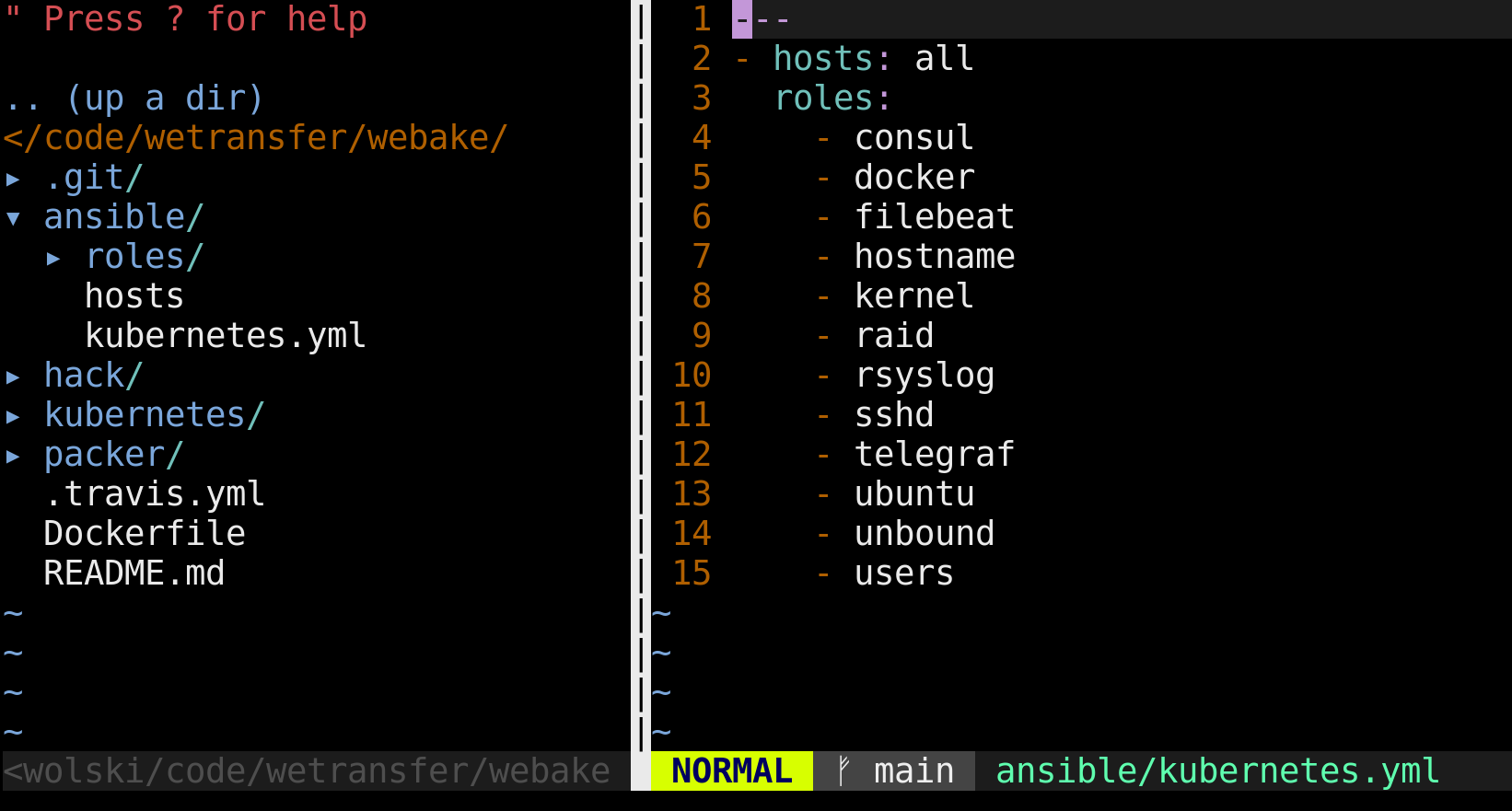
Monolithic Ansible roles are convenient. They're also not very composable. We had 2 such roles named 'common' and 'commonv3'. They consisted of DHCP, logrotate, syslog, ulimit, Unbound and other configuration. Our new design aimed to have well-scoped roles that are composed into per AMI playbooks. This pattern makes our codebase more readable and maintainable.
🎉 A Surprise Cluster Roll!
The life of a WeBake deploy started out as a humble, yet modern Kubernetes Job. Gone were the days of donning the chef's hat and SSHing into The Packer Machine. Now, a pull request is merged, WeDeploy applies a Job manifest, a WeBake pod is scheduled, Packer is run and 10 minutes later an AMI is published to AWS. Success! However, there was still one missing ingredient to make our own developer experience seamless.
Prior to WeBake, there had been an element of surprise to the experience of rolling out a new AMI. We maintain a monorepo named platform-kubernetes which contains our Kops cluster specification and manifests for our cluster-critical services. When deploying any change, a script had fetched the latest AMI from AWS and slotted its name into the Kops cluster spec. An unsuspecting Platform engineer rolling out an unrelated configuration change may get a jolt when they realized a new AMI is being rolled out too!
We wanted our new developer experience to be more explicit and less surprising. We envisioned an automated pull request a la depfu that updated the OS image reference in the Kops cluster spec every time a new AMI was baked instead of lazily pulling latest. A Platform engineer could then choose to merge the pull request and roll the cluster, ignore it or close it.
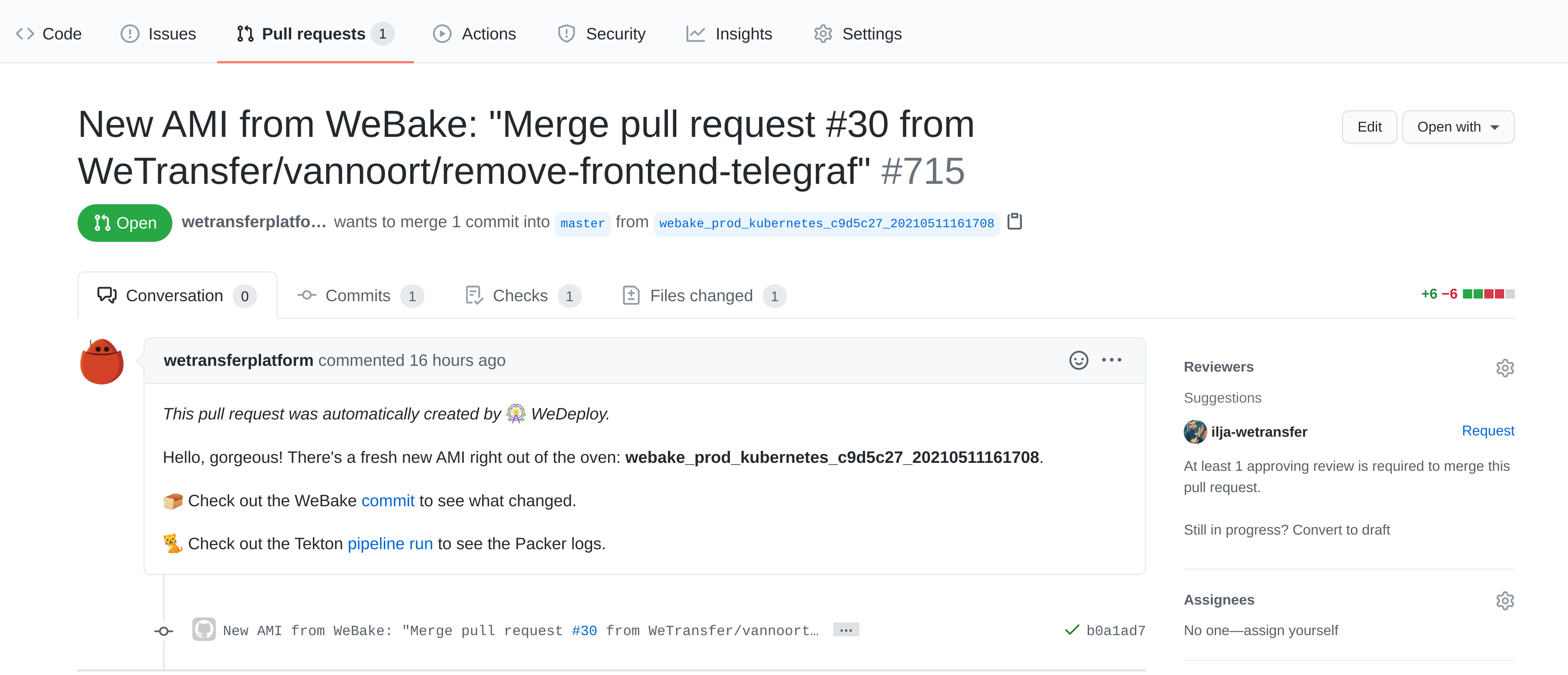
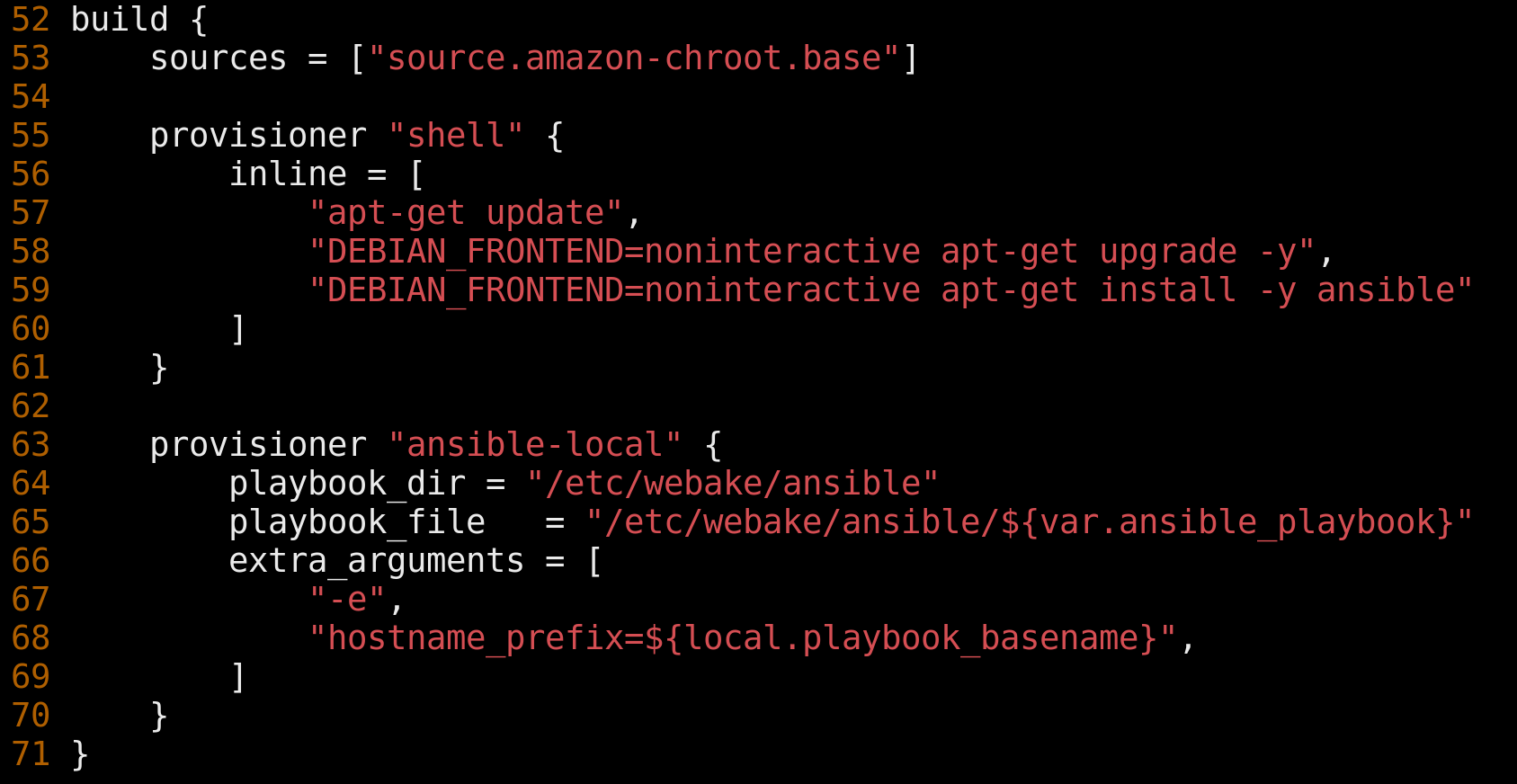
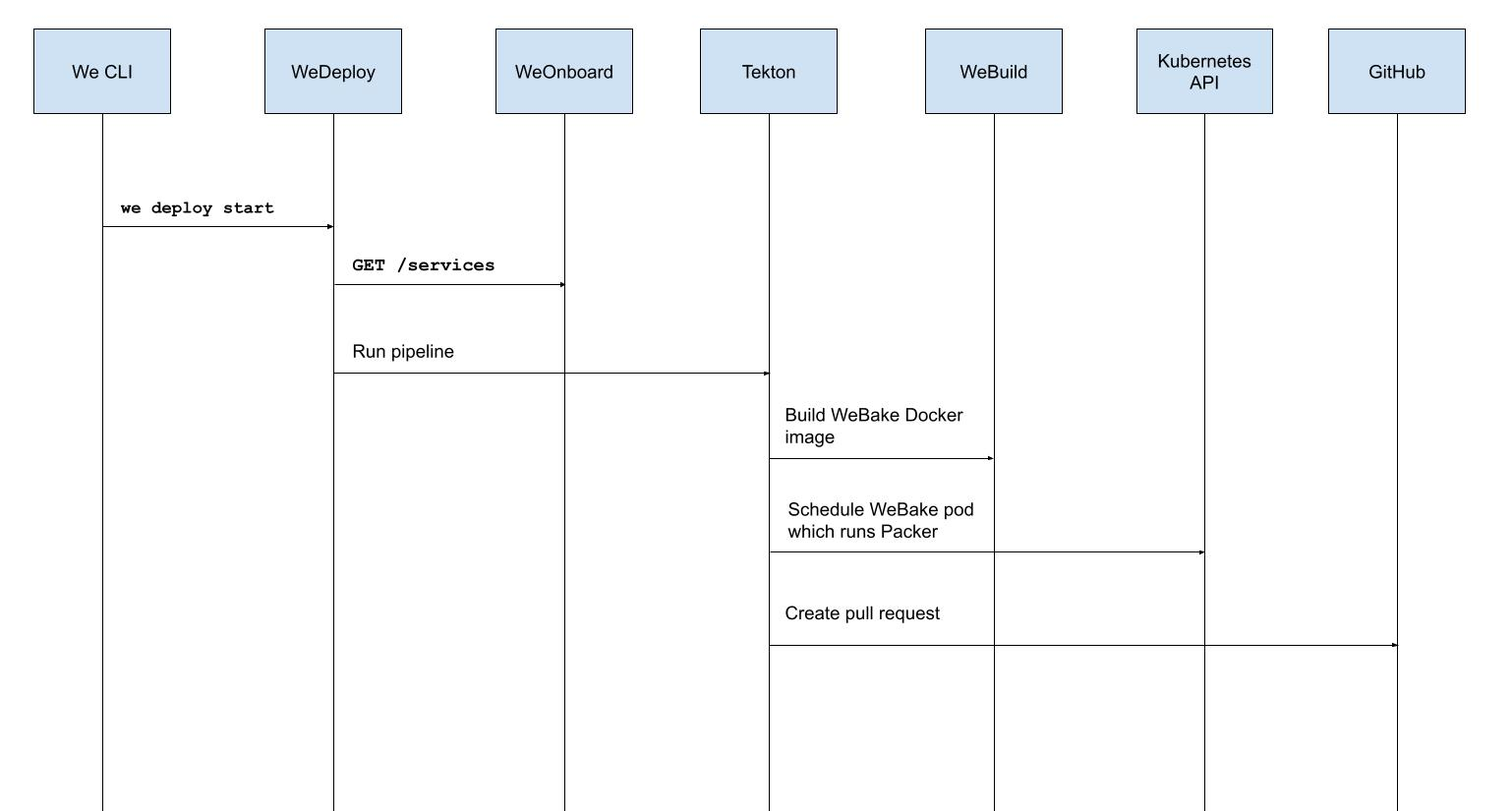
Our vision was realized when we deconstructed the parts of the WeBake deploy process and decided to more heavily invest in Tekton. First, we enhanced our service onboarding service named WeOnboard by adding support for service kinds. The original service kind **being Docker and a new service kind for AMI baking, aptly named AMI. When deploying a service like WeBake, the service's kind would be inspected and a Tekton pipeline for AMI baking would be run.
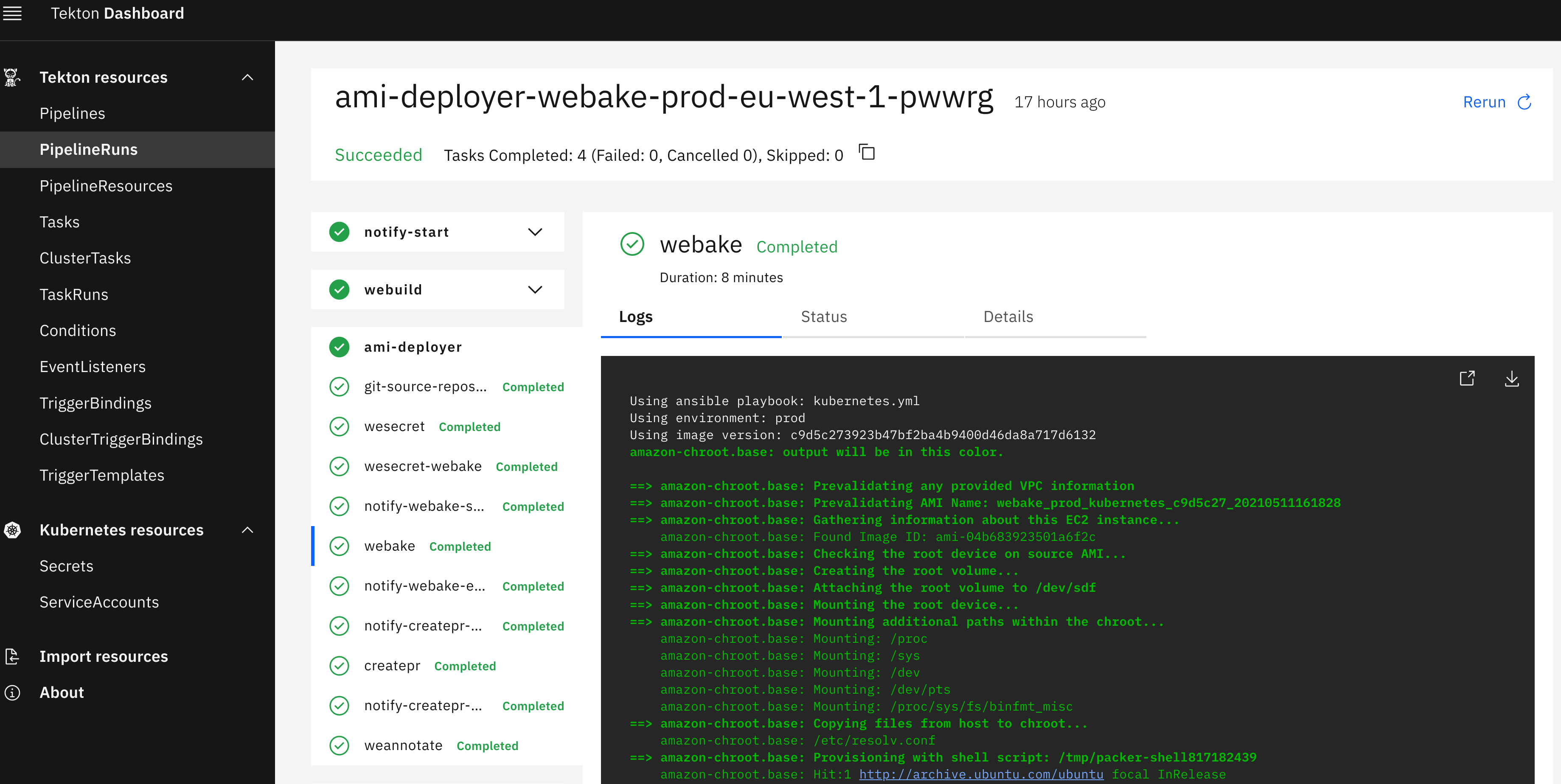
The first task in the Tekton pipeline is a Docker build and push. The next task schedules a WeBake pod wherein Packer is run. The pipeline culminates in a pull request being created against platform-kubernetes which replaces the existing image reference with the proper AMI name and thus makes our developer experience toil- and surprise-free.
👋🏻 Conclusion
Revamping our AMI baking infrastructure was an exercise in patience, good timing and calculated risk-taking. The Platform team had been chomping at the bit for years to make improvements in this part of our stack without ever finding a compelling reason to act; AMI baking was always "good enough." It wasn't until 16.04's expiration date approached that we jumped at our chance.
Now with WeBake, we have a firm base on which to rollout AMI changes large and small. What was once a very manual process can now be triggered with a merge of a pull request or a weekly cron. The easier these changes are to rollout, the more likely they are to occur, which is good for the Platform team at WeTransfer, and ultimately, our end-users.
Thanks for reading.