Before we begin it's imperative for me to admit that it took me longer to start writing this article, than to actually migrate the monolith.
So what's this all about then?
We migrated Wetransfer’s frontend - a ruby monolith + UI onto kubernetes. To understand why we decided to go ahead with the migration let's first rub a crystal ball and take a look into the past.
What we used to have
In the olden days we would run the monolith service directly on EC2 nodes and would release it via ansible. We - the platform team - had people physically coming to our desks or reaching out to us on slack and asking us to release a particular tag / github commit. That was the case for both staging and production environments. This meant that if you wanted to test and release the monolith 10 times a day, you'd have to talk to a platform engineer 20 times and in turn a platform engineer would have to press a button 20 times. It didn’t feel like a very mature set-up.
Improvements in iterations
A few years ago we went through the first iteration of improving our monolith infrastructure and putting it into a docker container. It was around this time that we started introducing Docker across the engineering org. This allowed us to drastically change our deployment strategy; we’d deploy via Travis, allow developers to release code themselves, somewhat conveniently create development stacks, and have consistency across environments.
While the new set-up was good, it was far from amazing. While we successfully put the monolith into a docker container we did not have any decent orchestrator. EKS was in its infancy, ECS already on its way out and the introduction of self hosted kubernetes (which we eventually went with) felt like a giant task, especially coupled with a general migration to Docker.
So we decided to make our own proudly home-grown little orchestrator that simply consisted of re-creating a monolith nodes Autoscaling Group (from now on i’ll refer to it as ASG) with terraform since the docker image tag changed. Releasing this to production would consist of pulling the latest code from github, building a docker image with it, pushing this image into ECR and creating a new Launch Configuration and ASG. We would wait until all new nodes were healthy and only then destroy the old ASG.
This whole process would take about 20 minutes and involved a few extra bash scripts which would fetch the number of nodes running in the old ASG and then inject it as the number of desired nodes into the new ASG and manage its release queue to automatically cancel all the builds that weren’t first or last in the queue.However, because of AWS resources being managed by terraform, we would only be able to run one deployment at a time since terraform locks state files.Developers would be able to provision custom development environments for themselves but that would contain 5 EC2 instances + some extra supporting infrastructure (i.e., load balancers, database etc.) Provisioning an environment like that would take around 40 minutes (mostly because of the database), but of course once it was provisioned deploying to it would be faster - approximately 10 minutes.
Before we migrated the monolith itself onto kubernetes, we re-defined a way on how to use development environments. My teammate Pablo wrote a really nice article about that project - internally known as WeStage - here.
Therefore, to summarise, we were facing the following issues:
- a proprietary solution that every new person had to spend time to familiarise themselves with.
- slow deployments to staging and production with only one consecutive deployment at a time.
- slow and expensive dev stacks that lack flexibility.
- hundred lines of terraform in the monolith repo that were coupled with the monolith service and looked like some sort of magic to the majority of developers.
We knew this could be improved. And with all the time that we have freed up from no longer needing to press the release button anymore, we embarked on a new journey of introducing kubernetes across our engineering org.
Preliminary migration work
All the new services that got developed were immediately onboarded onto kubernetes, contributing towards an increased confidence in the set-up amongst developers and thus reducing their fears of the unknown.
The introduction of WeStage propelled us to a place where any monolith PR could be launched on kubernetes in a matter of seconds.Kubernetes ran on cleaner AMIs with newer Ubuntu versions and newer telegraf versions, therefore providing better observability than the old stack.
In a sense this meant that all the preliminary work for the migration was already done. We had people confident in the set-up and somewhat familiar with kubernetes, we had an environment ready for monolith, and we had tools to scale pods horizontally depending on the load. All we had to do was make sure that the monolith could permanently run in kubernetes, and that the load was handled gracefully. Pretty easy, right?
Our Plan
A diverse team consisting of a frontend engineer, backend engineer and a platform engineer, approached the migration with full responsibility. Our plan was simple - we would deploy the monolith everywhere and fix all the problems as soon as they appeared. We also agreed to meet daily for a stand-up.

As previously mentioned, our monolith is big and actively used by both our developers and customers. With our monolith also being such a big beast, this meant that in reality, the majority of our time was actually dedicated to making sure that things worked as expected. It wasn’t about creating new things or re-writing old ones, but making rather making sure that the lift-and-shift of existing things didn’t end up breaking anything.
One of the most notable rewrites we did was for cronjobs.
Previously we had a separate EC2 instance specifically dedicated for running cronjobs. Kubernetes conveniently allows you to schedule cronjobs in a native way.I've previously mentioned that our monolith was already dockerized before we even began. However, we did go into the migration with a lot of unknowns and a hands-on approach to solving problems:
Westage doesn't allow creating cronjobs? That’s fine, let's go ahead and fix cluster permissions.
Monolith doesn't have permissions to access S3 bucket? That’s fine, let's just add those.
Something unknown or unfamiliar? That’s fine, let's pull in the right people who can unblock us.
Step by step approach
The migration of the monolith went ahead in phases - first we moved cronjobs and another piece of supporting infrastructure that was responsible for sending out notification emails. After that - the monolith itself and all frontend traffic.
The migration of frontend traffic was managed using tools we already had - namely HAProxy which always served - and continue to serve - as main points of ingress for all external traffic.
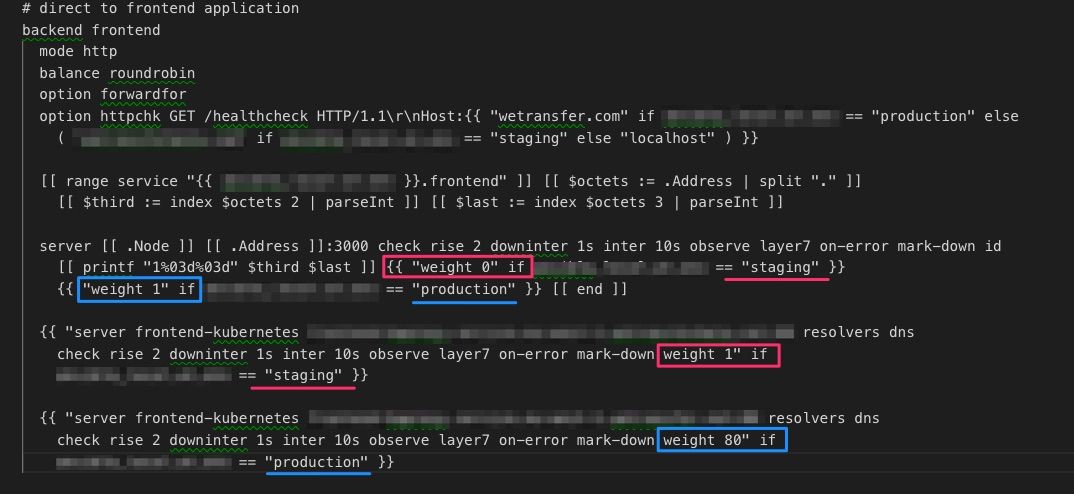
Here you can see how adding weight to either kubernetes or old infra backend allowed us to very gradually balance traffic and test the kubernetes set-up under loads.

After migrating parts of the traffic we would leave it be for a period of time (e.g. 24 hours) to make sure error rates weren’t outside of expected limits and that systems weren’t overloaded.
Things not going according to plan
As you can see, the process for us was very touch-and-go. Something which ended up being both a blessing and a curse.
It was great in the beginning but became a little confusing (and at times, a little overwhelming) by the end. If I could go back in time, I would start in the same manner, but probably introduce a Project Manager role earlier on. Someone who’d be aware of what everyone was doing, what had been done so far, and what else needed to be done.
As the migration project continued, some colleagues briefly joined to help with some tasks and then left again; I went on a short holiday and came back; people working with monolith but who weren’t involved with the migration had to be kept updated on what was happening and where we were in the process. It got a little messy at times, and this could’ve been handled a lot better with a dedicated project manager.
On a related note - people that were pulled in adhoc felt like their day to day flow was disturbed and their usual productivity affected. At the same time people that stayed on the project from the very beginning, often felt like the project wasn’t moving fast enough. Especially when we were approaching the end and spent the majority of our time simply observing things. Having a dedicated project manager could have also helped with organising people more efficiently and involving the right contributors at the right time.
And another one
The monolith is big. Very big. A lot of people contributed towards it and whenever something went wrong it was hard to pinpoint the exact cause. A bunch of other services heavily rely on monolith so in addition to testing the monolith on kubernetes itself, it was essential to test all other supporting services too. And to illustrate how easy it is for dependencies to break during such migrations let me simply refer to these three words - DNS name change.
I've talked about HAProxy as one central ingress for all external traffic. But what about an internal one? For a long time, we as a team, advocated for: cross service communications over internal networks, didn't shy away from creating VPC peering connections to accommodate that, and ran internal DNS for every iteration of the platform. That’s where the problem came in. Previously when we ran the monolith without kubernetes we used Consul for internal DNS and the service could be reached via SERVICE_NAME.service.REGION.wetransfer.net
After the migration we switched to native kubedns, with the new internal name for the service now being SERVICE.NAMESPACE.svc.cluster.local
As a result, this had to be changed for every service that needed to talk to the monolith.
Let's wrap it up
After all was said and done - we have now migrated our monolith on kubernetes... and we're really glad we did. We removed another big snowflake from our infra, and made the most critical service more resilient, more flexible, easier to scale and faster to release.
Most importantly - we achieved consistency across our environments. We went from around 100 individual nodes to about 800 pods spread equally around existing kubernetes cluster nodes that also host other products. Autoscaling is controlled via Horizontal Pod Autoscaler and not AWS ASG. Deployments in production take around 10 minutes instead of 20, and in staging about 5 instead of 15.
As mentioned above - kubernetes provided us with plenty of tools to make everyone's life easier. Not only do we now handle cronjobs in a much more cloud-native manner, but we also take advantage of other concepts such as requests and limits, Horizontal Pod Autoscaler, a variety of deployment strategies, and so on.
So with that the modernisation of our monolith is now complete. Now you know what infrastructure is used every time you transfer a file. Hope you enjoy both using wetransfer.com and reading about the technicalities that lie under its hood.
Oh, and by the way...we’re hiring