WeTransfer took the plunge to adopt Kubernetes in mid-2018. Our initial adoption efforts focused on production-readiness. We built out tooling to provision multi-region clusters and deployed critical supporting services like CoreDNS, Kiam and nginx Ingress. Within 6 months, the first user-facing application was launched. Our attention then turned to developer productivity. By years' end 2019, we reduced service-onboarding time on Kubernetes to a few hours enabling developers to launch tens more applications.
Unfortunately, favoring stability and developer productivity meant that we neglected upgrading Kubernetes. As of late 2020, we were still running 1.11.8. With every Kubernetes release that came and went, we regrettably missed out on API Server security patches and useful features like shared process namespace, and official documentation grew evermore irrelevant.
Before the Kubernetes community could create even more distance from 1.11.8, we committed ourselves to a much needed set of upgrades during the last quarter of 2020. This is a story about how we finally upgraded to Kubernetes 1.18.
🏗️ The Setup
Our Kubernetes cluster architecture is fairly traditional. We've got a development, staging and production cluster in each of 2 AWS regions. The development clusters are a proving-ground for experimental code; in other words, it's not uncommon to see pods in the "CrashLoopBackoff" state for long stretches of time. Our staging clusters are integration environments and production is, of course, serving real traffic. In terms of scale, our workloads in eu-west-1 are several times larger than those in us-east-1.
Platform engineers also have the ability to spin up personal, 6-node development clusters where they can experiment with upgrades and cluster-critical services so as not to disrupt the deployment flow for our engineers: dev → stag → prod.
All of our clusters are configured and provisioned using Kops. We maintain a monorepo-of-sorts containing our Kops cluster spec as well as the manifests for cluster-critical services. When configuration changes are pushed, a CI/CD job is kicked off and the changes are applied. Should there be a change to an AMI, CI/CD too performs a rolling update of the cluster. However, upgrading would require a different kind of rolling update. One that we hadn't done before.
📄 The Plan
Prior to rollout, we wrote and shared an internal RFC entitled Upgrading Kubernetes. In the document, we entertained 3 upgrade options: to migrate either onto a new EKS- or Kops-based cluster, or to perform an in-place Kops upgrade. Ultimately, we chose the latter, favoring time-to-completion and our familiarity with Kops.
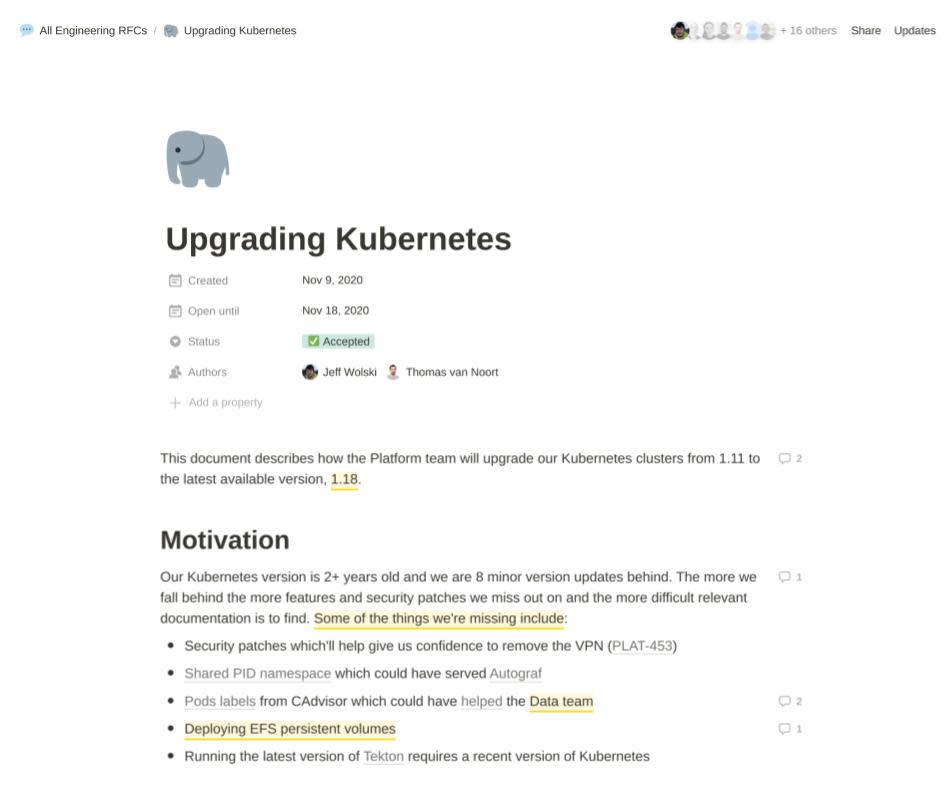
The decision to perform an in-place upgrade was of course predicated on our ability to perform one successfully. And we gained the necessary confidence by outlining the following plan:
Before an upgrade
- Decide on a minor version based upon the amount of perceived risk
- Review Kops and Kubernetes release notes for breaking and significant changes
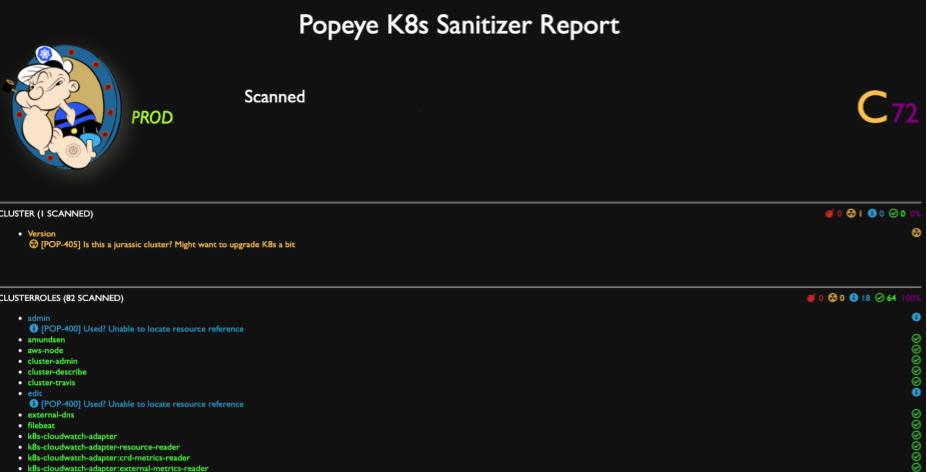
- Review Kubernetes API deprecation notices using Popeye
- Review critical services like CoreDNS and nginx Ingress and their potential dependence on specific Kubernetes versions
- Provision a personal development cluster to rehearse the upgrade
During an upgrade
- Take backups of the Kops state bucket and etcd (Only necessary before 1.12. Kops automated etcd backups for 1.12+).
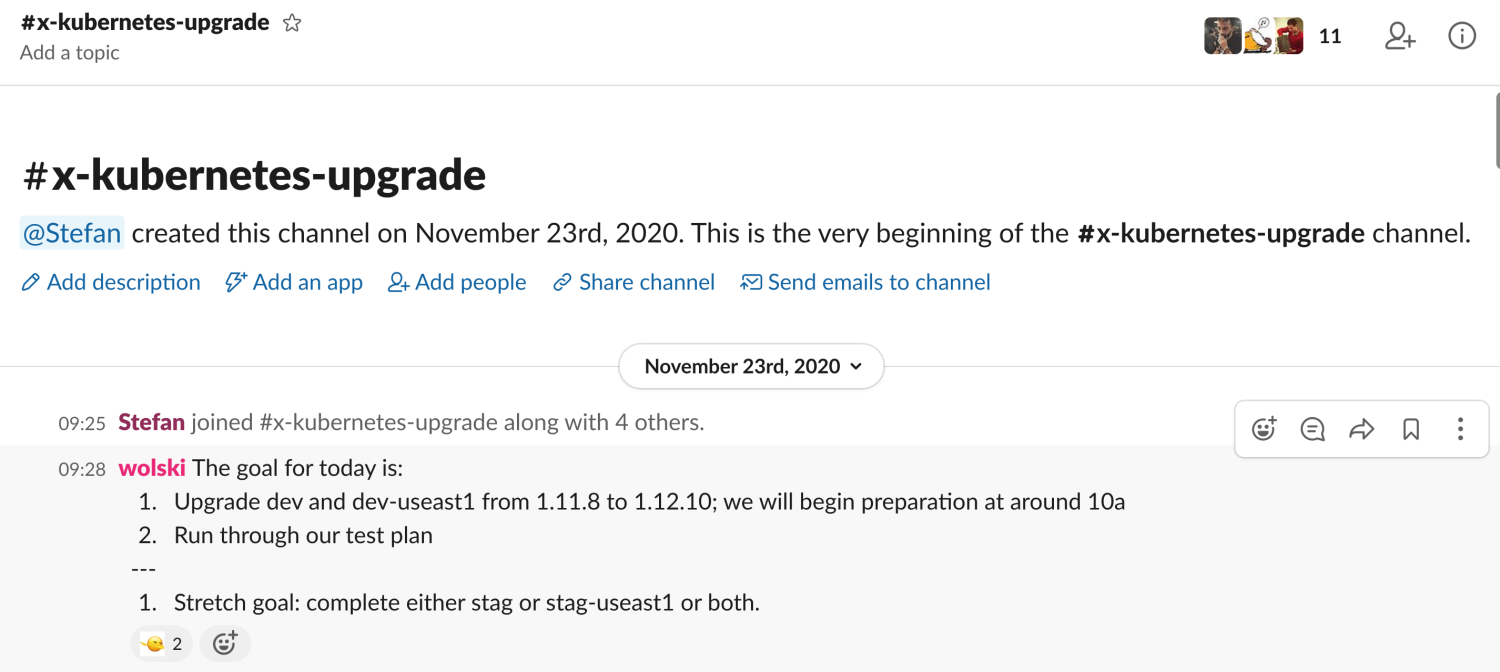
- Invite engineers to a dedicated "Kubernetes Upgrade" Slack channel and record every action taken
After an upgrade, ensure:
- 1st and 3rd party software that relied on the Kubernetes API were functional
- Tools like kubectl and k9s were functional
- DNS for AWS internal zones, internet domains, cluster-local addresses and out-of-cluster Consul addresses were resolvable
- Kubernetes resources like "Deployment", "Ingress" and "Service" could be applied and were functional
And we would perform the upgrades with the following cadence:
- Day 1, AM: upgrade our development clusters starting with us-east-1
- Day 1, PM: upgrade our staging clusters
- Day 2: regression test
- Optionally, instate production deploy freeze. This was only done for our first upgrade given the newness of the initiative and the risk involved.
- Day 3: upgrade our production clusters
With a plan in place, we were ready to embark on the path to 1.18. As luck would have it, the first upgrade was the riskiest. Kubernetes 1.12 required a major version bump of etcd, which necessitated master downtime. The prospect of the unexpected happening and a prolonged disruption to our engineer's ability to deploy and manage their applications sent shivers down our collective spines 🥶.
👨🏿🏭 The First Upgrade
Just as with one's first-born, we demonstrated extreme caution with our initial upgrade. It called for manual intervention and a controlled roll-out from our workstations. Here's how it went down.
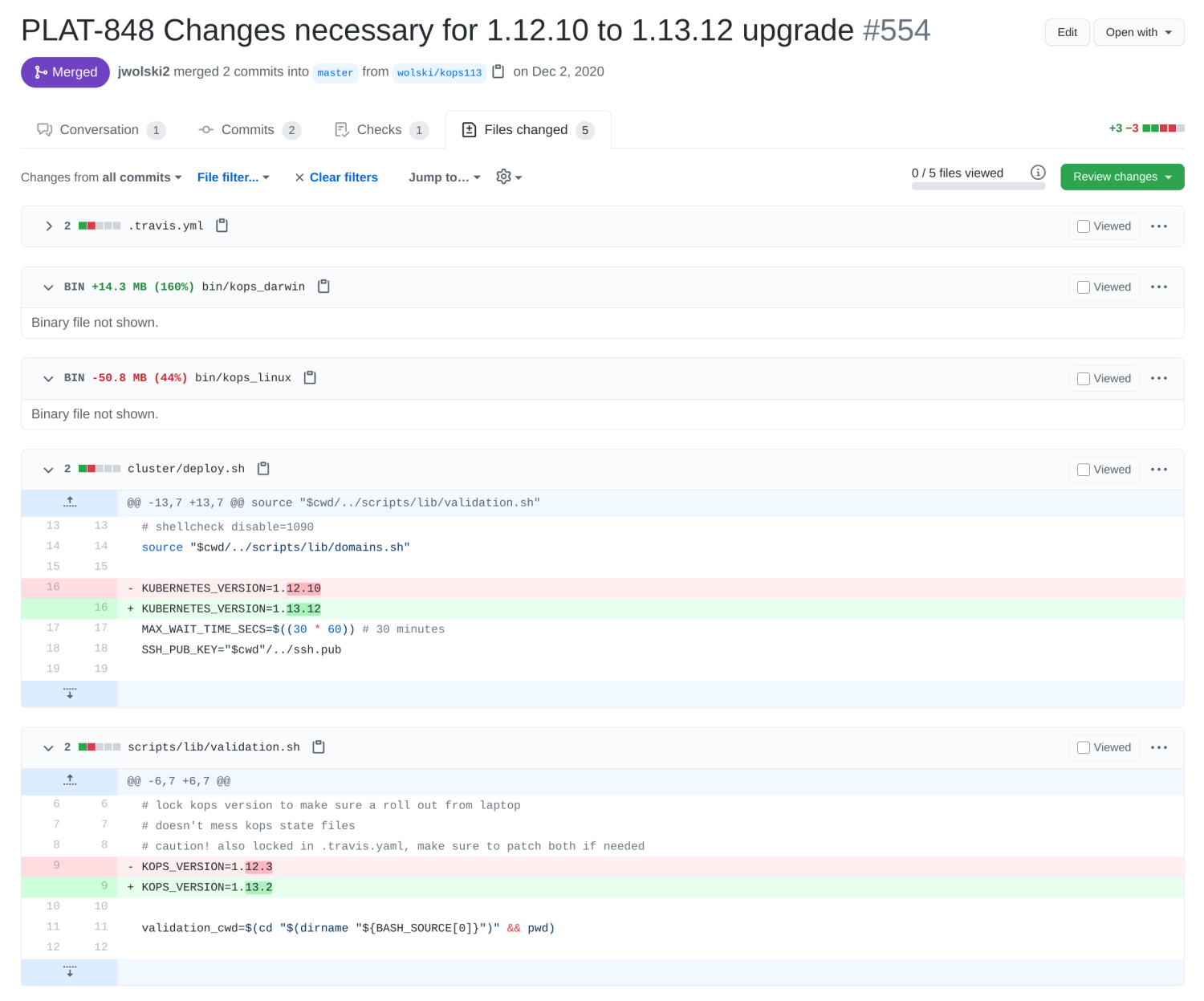
For starters, we ran the upgrade with a forked version of Kops, not the most reassuring way to start a major initiative. We cherry-picked commits (1, 2) which tacked on support for the "externalCoreFile" field in the Kops cluster spec. This allowed us to inline our custom CoreDNS "ConfigMap" and prevent CoreDNS from being reset to 'factory defaults' upon upgrade. (We no longer needed the fork upon reaching Kops 1.15).
On the day of the upgrade, we performed the following steps:
- Run "kops edit cluster" and update "kubernetesVersion" to "1.12.10".
- Run "kops update cluster" to sync state to Kops state bucket.
- Add a temporary IAM policy to prevent nodes from being removed from "Service" load balancers while the masters were unavailable.
- Run "kops rolling-update" against the masters.
- Wait an agonizing 7 minutes for the new masters to startup and join the cluster.
- Run "kops rolling-update" against the nodes and babysit until done. 👶🏼
- Perform battery of regression tests before moving onto the next minor release.
The upgrade itself went smoothly, but we ran into one unexpected snag. Our cluster was under-provisioned and as the upgrade rolled out, there were insufficient CPUs to satisfy outstanding CPU requests for a few auto-scaled "Deployments". When this happened, we paused the rolling update (read: ^C), scaled up the cluster and resumed the upgrade.
We felt good about our chances with the remaining upgrades once the riskiest was out of the way. None of the subsequent upgrades required manual intervention and we were confident in handing over the upgrade to our CI/CD system. Automation made the process less grueling, though the upgrades themselves were not without their quirks.
🕸️ The Remaining Upgrades
Our in-house tooling already allowed us to perform rolling updates via automation. Therefore, not much work was required to perform an automated upgrade. Comically, the custom Kops binary we built threw us for a loop. We decided the easiest distribution mechanism for it was to commit it to our repository, given its use was only temporary. However, its size exceeded GitHub's 100MB size limit. We used a tool called upx to compress it, which allowed us to move on and focus on the next upgrade.
From 1.12.10 to 1.13.12 The upgrade to 1.13.12 went smoothly except for intermittent issues with Kops cluster validation. Occasionally, Kops would report "http2: no cached connection was available". After scouring numerous issues (1, 2, 3, 4) in the Golang and Kubernetes GitHub repositories, we settled on disabling HTTP2 altogether by passing Kops the DISABLE HTTP2 environment variable.
From 1.13.12 to 1.15.12 We skipped 1.14 after confirming there were no breaking or significant changes to be cautious about. The upgrade to 1.15.12 presented a few challenges. Kops 1.15 bundled along with it an upgrade to CoreDNS which forced us to refactor our CoreDNS "ConfigMap". Its "proxy" plugin had to be ported over to the "forward" plugin and several new "server blocks" had to be introduced to replace our previously monolithic server block. There was also a trivial change to the Kops API group from "kops" to "kops.k8s.io".
From 1.15.12 to 1.16.15 The upgrade to 1.16.15 initially felt daunting. Several API groups for "DaemonSet", "Deployment" and "Ingress" resources still in use by WeTransfer had been deprecated. We expected days of hunting down manifests and pouring over obscure errors from the Kubernetes API. However, we found that it wasn't nearly as much effort as we thought. A simple find-and-replace of "apps/v1beta2" or "extensions/v1beta1" to "apps/v1" in our monorepo resolved most of the incompatibilities. And we found the upgrade to the "Ingress" API group could be delayed until Kubernetes 1.22.
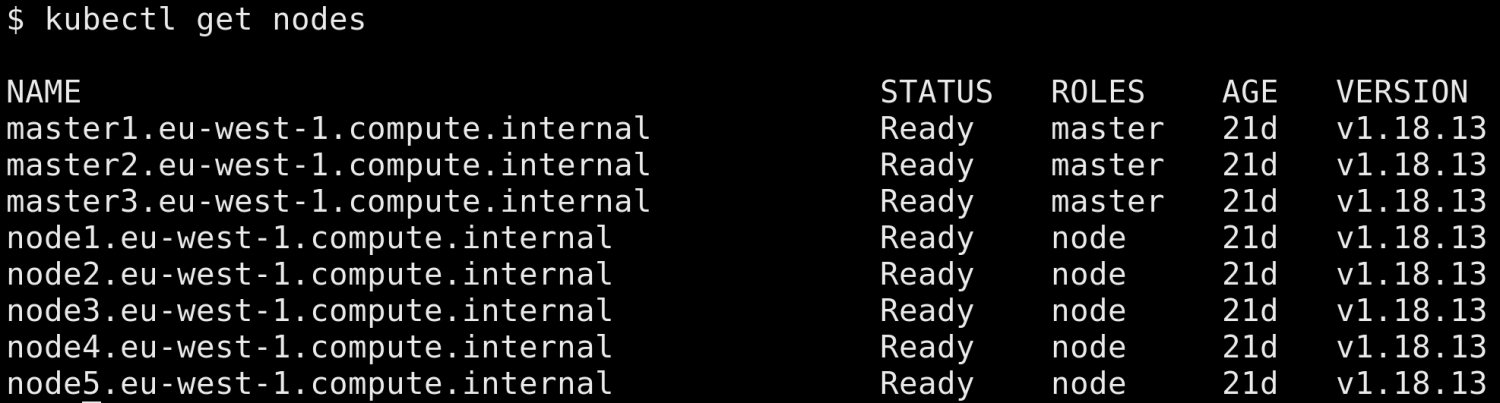
From 1.16.15 to 1.18.13 Our final destination was in our sights. We skipped 1.17 and charged ahead to 1.18, the latest version supported by Kops. The upgrade left behind only minor carnage: CAdvisor label names such as "pod_name" and "container_name" had been deprecated. And the upgrade also broke our infrequently used Kubernetes Dashboard and experimental use of Tekton, but fixes were soon to follow.
We had been staring down the barrel of this upgrade path for 2.5 years and now we'd enter the new year running 1.18. It was cause for celebration!
👨🏾🎓 Lessons Learned
Thankfully, there were no hard lessons learned during this experience. But we'd like to share a few practical tips for anyone forlornly looking at distant Kubernetes releases.
- Ensure you have enough cluster capacity to handle a rolling upgrade.
- Use the "maxSurge" field introduced in Kops 1.18 to speed up your rolling upgrade.
- Rotate your 'Lead Upgrade Engineer' to share the burden and get fresh eyes on the problem.
- A (dev) cluster kept in an unkempt state obscures your ability to detect whether an upgrade was successful. Adopt proper cluster hygiene.
- In a system as complex as Kubernetes, some errors can be classified as transient or unimportant (read: YOLO'd) and others need more strict attention.
- Treat your clusters as immutable and disposable rather than as precious heirlooms. If we had the tooling, the time and the foresight to turn-up a new Kubernetes cluster in minutes, we probably would have opted for a migration rather than an in-place upgrade.
- Set an upgrade cadence for your team so that you don't end up in this position again.
🎉 Conclusion
Kubernetes is a complicated beast, and WeTransfer is not alone in initially prioritizing stability and developer productivity, at the expense of staying current. Moreover, committing to a series of critical upgrades becomes even more daunting when real users are depending on it going well. We hope this article gives you the confidence to meet us at 1.18 and beyond!
If you liked what you've read and are interesting in joining the Platform team at WeTransfer, see our open roles here.