
The COVID pandemic changed the way WeTransfer engineers work. Pre-COVID, we had grown accustomed to the conveniences provided by the safe confines of our corporate network, and good intent was assumed within. However, being displaced from our office forced us to reconsider basic assumptions about developer experience and infrastructure security.
Given that life in quarantine was already difficult, how could we ensure we weren't making it worse by failing to address the technical challenges presented by our new reality? One answer to that question was to enable Kubernetes from home.
🥫Opening Up Kubernetes
Engineers at WeTransfer would typically access Kubernetes from within our corporate network using tools like kubectl and k9s. Underlying those tools is a kubeconfig. The kubeconfig specified how to locate our IP-restricted clusters and how users should be authenticated against them.
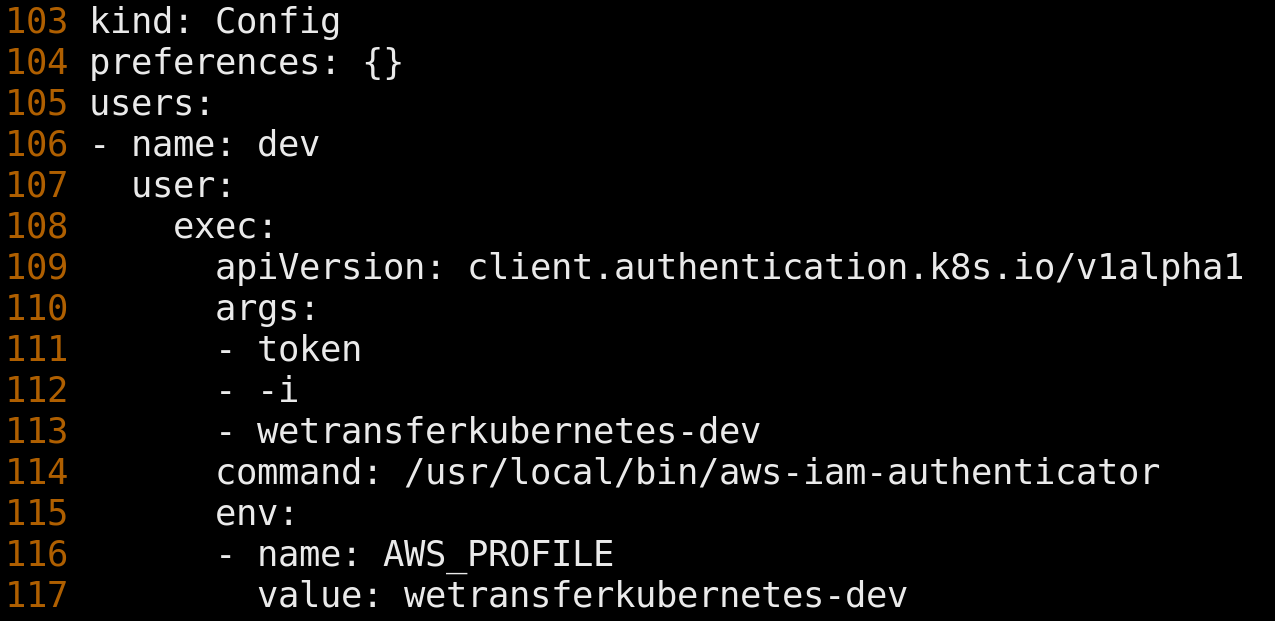
Upon invocation, such as with 'kubectl get nodes', kubectl shells out to AWS IAM Authenticator, an open source tool that integrates with identity management services like AWS IAM and STS. The tool establishes credentials on an engineer's behalf and passes control back to kubectl. Kubectl sends the authenticated request to the Kubernetes API Server which then delegates credential verification via a webhook to the server-side component of AWS IAM Authenticator. User credentials, and the AWS IAM user they represent, are mapped to an RBAC group, and the user is authorized access to Kubernetes resources.
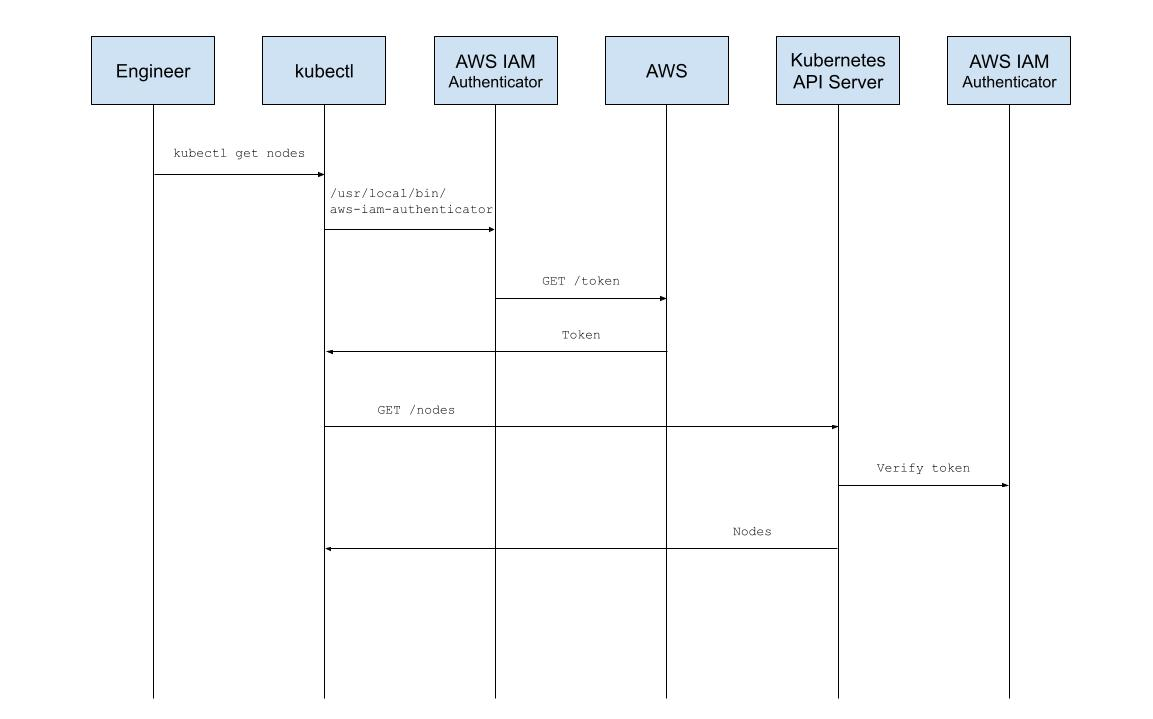
This setup worked perfectly well, but simply opening it up to engineers at home gave us pause. Malicious users could poke directly at the API Server looking for unauthenticated endpoints or vulnerabilities and could potentially impact cluster operations. Our first step towards cluster-hardening was to upgrade Kubernetes. The next was to avoid exposure of the API Server by placing it behind our corporate access proxy. Then to facilitate access, we wrapped the client-side AWS IAM Authenticator tool with our in-house We CLI.
⌨️ Interacting with Kubernetes
We CLI is a tool, written in Go, that unified and replaced a plethora of half-baked shell scripts in order to provide a friendlier user experience and common interface for interacting with 1st-party Platform APIs. With We, engineers can onboard themselves, generate configuration, trigger Docker builds and initiate deploys. Upgrades to We are also not a problem as they are automatically distributed to engineers' laptops by leveraging our IT team's software distribution tool, Jamf. All these conveniences combined made it a natural choice to include **as part of our solution to facilitate access to Kubernetes.
To bootstrap We, engineers must configure a client ID and secret which identifies We to our access proxy. Engineers must also generate a kubeconfig, which was altered to shell out to We instead of AWS IAM Authenticator; the kubeconfig can, of course, be generated by We too, e.g. we kubeconfig generate.
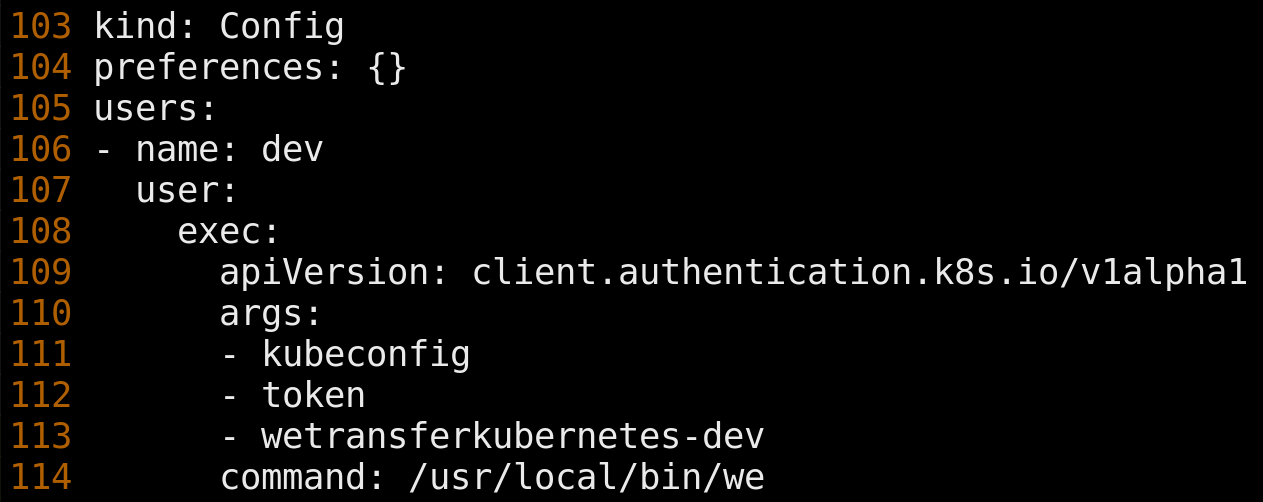
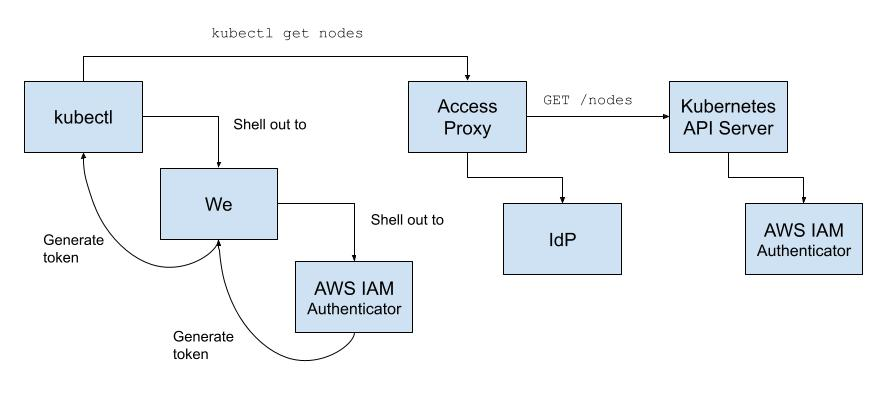
When kubectl is invoked, We determines if the engineer has logged in and if not invokes 'we login'. Provided valid credentials and a response to a 2FA challenge, a short-lived token compatible with both our access proxy and Kubernetes is generated and sent along by kubectl. The resulting flow is nearly identical to the one previously described.
😵 Not Quite Interacting with Kubernetes
Freely interacting with a remote Kubernetes was welcomed by our engineers. However, within the first few days of rolling out a new We version, a new kubeconfig and supporting infrastructure, early adopters began reporting errors from 'kubectl exec':
Upgrade request required
It wasn't long after wiping the 🍳 from our faces that we stumbled upon a well-documented issue in the land of nginx Ingress Controllers claiming that websocket headers, 'Connection' and 'Upgrade', would be dropped in transit from ELB through nginx towards the Kubernetes API Server. Thankfully, among the comments was solid advice (from m1schka). It pointed us down the path of connecting the Kubernetes API Server, instead, to an ingress controller with a TCP listener.
The mistake on our part was a configuration oversight: the new ELB listener configuration did not match the old. Though the fix was somewhat of a 🤦♂️ moment and didn't require deep investigation, HTTP traces clearly show where protocol negotiation goes wrong. When kubectl exec is invoked, a POST request is sent to /api/v1/namespaces/<namespace>/pods/<pod>/exec. With an HTTP listener, the conversation goes something like this:
POST /api/v1/namespaces/<namespace>/pods/<pod>/exec?command=<command> HTTP/1.1
Authorization: Bearer token
User-Agent: kubectl/v1.19.3 (linux/amd64)
X-Stream-Protocol-Version: v4.channel.k8s.io
HTTP/1.1 400 Bad Request
{"kind":"Status","apiVersion":"v1","metadata":{},"status":"Failure","message":"Upgrade request required","reason":"BadRequest","code":400}And with a TCP listener traces look different. Once the connection is upgraded successfully, a SPDY conversation proceeds between kubectl and the Kubernetes API Server:
POST /api/v1/namespaces/<namespace>/pods/<pod>/exec?command=<command> HTTP/1.1
Authorization: Bearer token
Connection: Upgrade
Upgrade: SPDY/3.1
User-Agent: kubectl/v1.19.3 (linux/amd64)
X-Stream-Protocol-Version: v4.channel.k8s.io
HTTP/1.1 101 Switching Protocols👀 Auditing of Various Kinds
The effort to enable Kubernetes from home also created an opportune time to up our observability game. We added audit logging in order to give us insight into every action taken against the API Server: what was done, when it was done and who did it. Enabling audit logs and getting them to flow to our Elasticsearch cluster required trivial changes to our Kops cluster spec and to Filebeat, our log-tailing daemon:

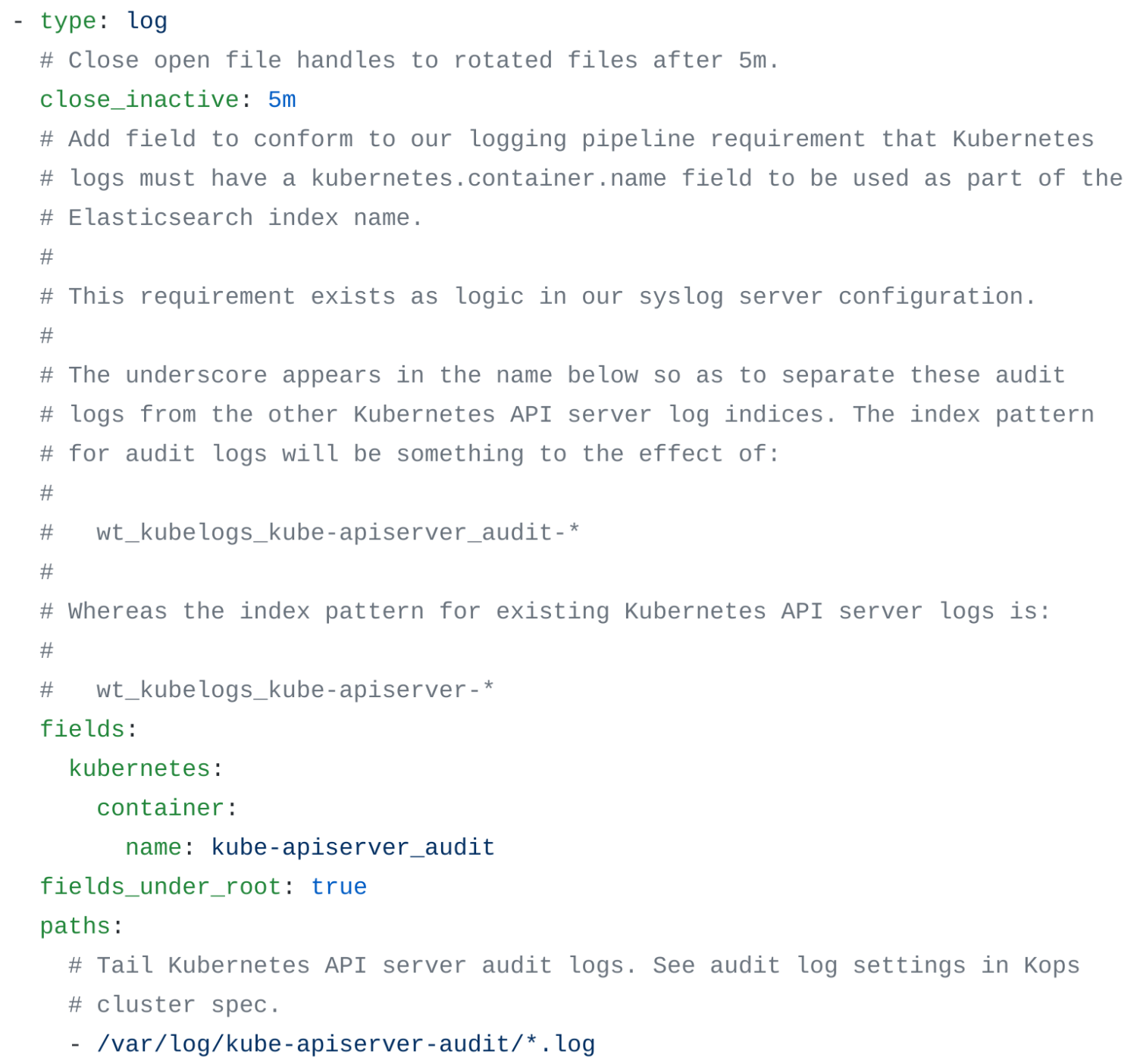
Once the flood gates for audit logs were open, we were surprised by the high rate at which logs were produced. The naive policy we set in our Kops cluster spec led to logs that included request-start and request-end documents every time, for example, kubelets called into the API, which was often. Verbosity aside, having the logs has already proven useful. For example, we used them to determine the desired access rights for one of our internal applications which, without audit logs, is an exercise that is often frustratingly opaque. Request-level insight is a big win for securing our cluster.
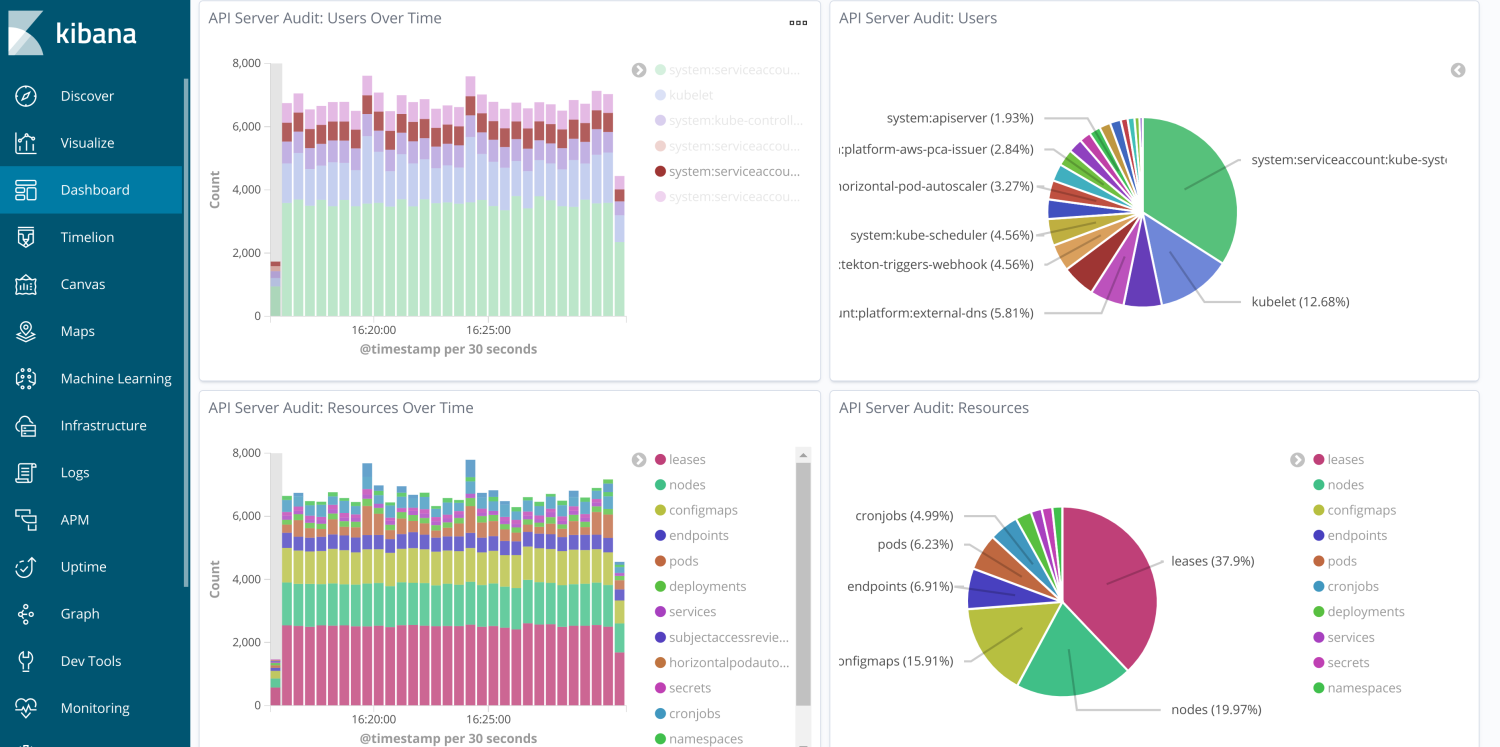
The final piece of the auditing puzzle was to recruit our Security team to ensure our solution worked as advertised. They checked the integrity of our authentication and authorization methods, attempted to access inaccessible endpoints and checked up on all the standard TLS fare. The solution was given a 👍 despite relatively minor issues (that would soon be fixed) around weak ciphers.
🎉 Conclusion
Traditional methods of providing remote access to our corporate services and infrastructure proved insufficient when the pandemic hit. In particular, engineers faced bottlenecks in their productivity and inconsistent, confusing approaches to access control; some services were IP-restricted and others not; some websites would "hang" and others not. The implicit nature of IP-based restrictions not only imbues a false sense of security, but causes headaches for maintainers and users alike.
The past year presented us with challenges of all sorts. The one here addressed a very disruptive change to our work lives and ultimately led to a solution that felt seamless and secure. The step we took was not in the direction of extending our corporate network further out towards our engineers at home, but one that drew us ever closer towards a Zero Trust model.
Thanks for reading. If you dig solving problems like this, then you might be interested in joining the Platform team here at WeTransfer. If you fancy a new role, see our open ones here.



