The Platform team at WeTransfer maintains the infrastructure underlying products loved by millions of users. We platformers also provide other engineers with tools to leverage the platform: we make it our responsibility that they can deliver their work confidently. Inspired by Heroku Preview Applications and Netlify Deploy Previews, we recently decided to up our own development workflow game.
We've developed WeStage, a service that automatically deploys a live preview of proposed changes for any application's codebase: it shortens the feedback loop during code reviews and keeps developers in their flow. This is how we designed and delivered WeStage during the last quarter.
An opportunity
The infrastructure that hosts all our products is conventionally partitioned in three environments: production, staging (where release candidates are deployed before reaching production), and development (where less stable workloads can run).
Our stack has also evolved along a conventional arc: from VMs to containers to Kubernetes, where we currently host about 50 microservices and going up. The latest modernization wave (early 2018) started with us Dockerizing our RoR monolith: this opened the door to creating dynamically-provisioned, isolated development stacks, where developers could independently push a Docker image of their working branch and share their environment with other colleagues to test and get feedback.
Developers themselves provisioned this environment with the use of Terraform specs for AWS resources replicating the production environment, namely: a set of 5 EC2 instances (each running a part of the monolith), an Elastic Load Balancer, an RDS MySQL instance, an ElastiCache instance, and a CloudFront distribution
Development environments gave engineers a powerful tool to improve their development workflow, but their architecture remained lacking in a few ways:
- Each engineer had a single stack, limiting its use to testing one code branch at a time
- Using this environment involved the maintenance of all its infrastructural components, making it slow to use and burdensome (Terraform is not the technology developers are the most comfortable with, nor should it be)
- Development environments weren't free to provision, making them financially wasteful for the little traffic they handled
Each of those shortcomings presented an opportunity to improve the internal platform. We gave ourselves the task to make development environments:
- More flexible, allowing simultaneously preview multiple proposed changes
- Faster, by leveraging the existing infrastructure
- Cheaper!
Since development environments are part of engineers' every day, any incremental improvement would compound for each one benefiting from them. We put ourselves in their shoes and pondered what the perfect development environment would feel like.
Effortless UX
Striving for operational excellence isn't synonymous with thinking about infrastructure all the time. For software engineers, developing new features, iterating on them, and submitting them for review is a time when, more often than not, operations are noise rather than signal: we'd rather focus on a code editor, the comments on our code, and a running instance where proposed changes are visible and testable.
On the contrary, the existing development environment made developers constantly switch context and deal with shell scripts and Terraform (and obscure errors coming out of them 😱).
For every product, we follow a delivery workflow centered around Pull Requests (PR): proposed changes to an application are submitted for review on GitHub before merging them upstream for release to staging and production environments. Could the deployment of an ephemeral instance of the application be seamlessly integrated into this established workflow?
Here's how we picture an ideal developer experience:
1. I develop a cool feature for the application collect , on a code branch called cool-feature, and open a PR over the main branch.
2. I place a label on the PR, indicating that I'd like a preview to be deployed.

3. I receive status updates and a link to the preview when it's ready: my colleagues and other stakeholders can view and test my work at cool-feature-collect.example.com
4. For each feedback addressed and pushed to the repository, the preview is kept up to date with the evolving code under review.
5. When the PR is approved and merged, all resources allocated to previewing are freed up.
Now, all it takes for engineers to deploy a live preview is to label their PR... once! In other words: to keep developers focused on their code, we concluded that the best UX for this service was none and challenged ourselves to make its use effortless (and hey, we're surrounded by talented colleagues who know a thing or two about beautifully obvious tools, so why not take a cue?).
We gave ourselves three months to deliver WeStage, so we couldn't put many unknowns in the mix. A quick survey of the stack made it plain that we were well equipped to achieve this.
Building WeStage
We have leveraged three features of our internal ecosystem:
- Code repositories share a common structure: there is one per WeTransfer service, and each contains a Dockerfile and a structured folder with
kustomizetemplates for Kubernetes manifests - We maintain a Kubernetes cluster in the staging environment, which hosts long-running instances of services
- Code is hosted on GitHub, which provides APIs and events related to PRs
In other words: we have a clear view of what needs to be deployed (code at a given point in history), where we can deploy it (shared staging infrastructure), and when to deploy it (according to GitHub). Here's how it works under the hood:
WeStage is a Golang application comprising 2 parts: a server exposing an HTTP API, and a worker doing the heavy lifting. The WeStage server is registered as a GitHub application and configured to receive notifications for every Pull Request event. When it receives an event for a PR that has been labeled westage, it schedules a new instance of the WeStage worker against the Kubernetes API. The worker then goes through the following steps:
- Notify GitHub that a Deployment and a Check are starting on the PR.
- Fetch the codebase at the git reference (commit SHA or git tag) specified in the PR event (clever trick: instead of git-cloning the repo and checking-out the git reference, we directly download a zipped archive of the repo for that reference: for our longest-lived mono-repo, this amounts to a 15X speed increase!)
- Build a new Docker image for this git reference, from the Dockerfile found in the repo.
Inspect the Kubernetes folder looking for kustomize templates:
- render the Kubernetes manifests needed to deploy the application by using the kustomize golang packages
- for each pod spec found among the manifests, inject environment variables specific to WeStage, such as the preview's URL (letting an application's code recognize that it's running in such an environment)
- modify all resources to avoid collisions with existing resources on the target cluster (more on this below)
- optional: render auxiliary services as well, such as an isolated MySQL instance
- Apply the resulting manifests from step 4 on the target Kubernetes cluster.
- Wait for all resources to be live, and for ingress hosts to be resolvable.
- Report back to GitHub that the Deployment is up and running, and that the WeStage check on the PR passed successfully.
- If any of the above failed, mark the GitHub Deployment and Check as failed and notify the developer, with a link to WeStage debug logs related to this preview.
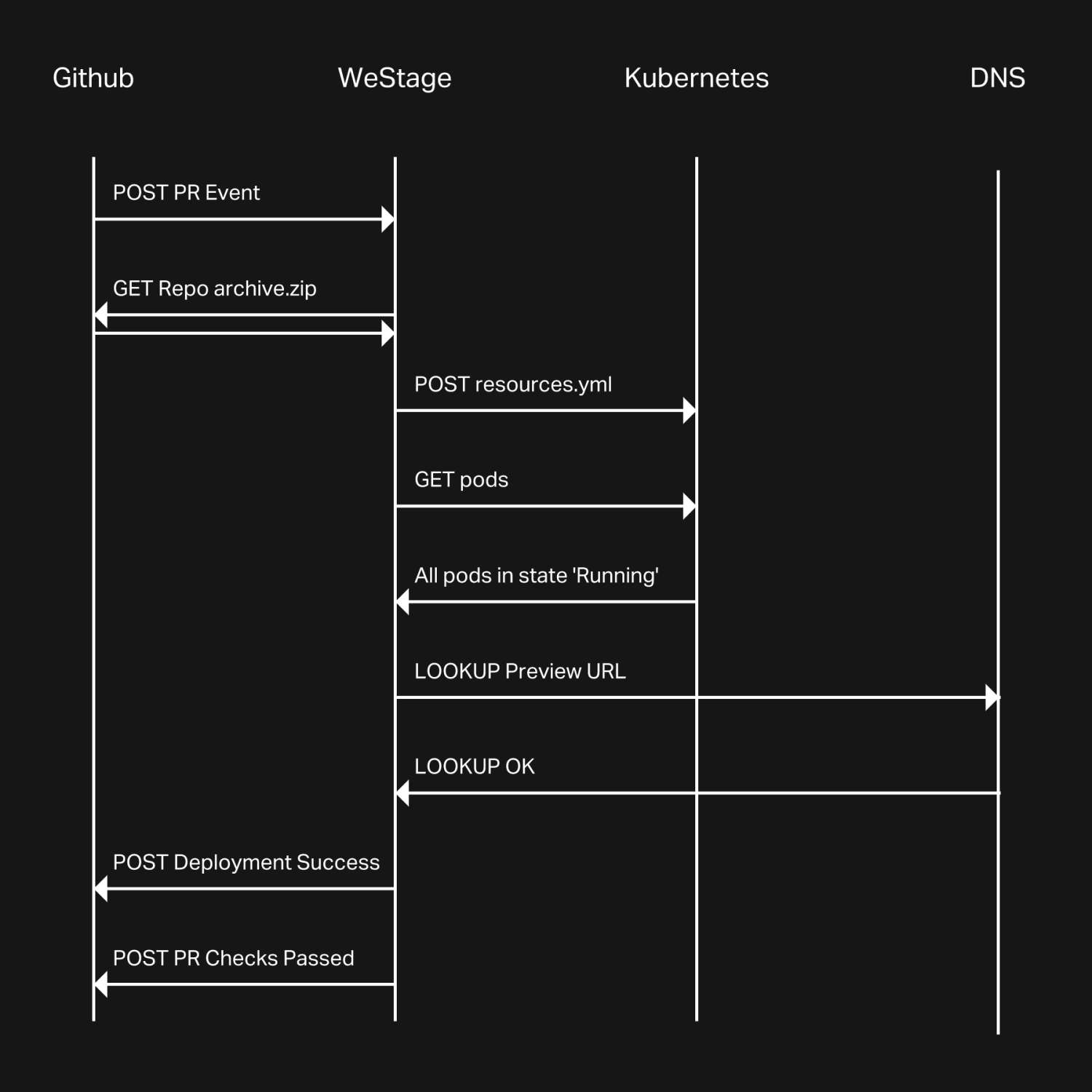
After the PR is approved and merged, WeStage receives a new notification from GitHub signaling that the PR is closed: all scheduled preview resources are then automatically deleted from the cluster. Rinse and repeat.
The nitty-gritty
Since we're leveraging the staging Kubernetes cluster where long-lived instances of our products already run, the isolation of resources is crucial to guarantee that ephemeral previews don't collide with their long-lived siblings. They can clash at two levels: at the namespace level, where resources cannot share the same name, and at the ingress level, where previews can't be exposed through the same hostname.
Since WeStage renders the manifests for all the preview resources, it can apply some transformations before applying them. For each preview, a new namespace is created on the cluster, with a unique name: westage-{application}-{pull-request-branch}. All ephemeral preview resources get assigned to that namespace, where they will remain isolated from their long-lived siblings that run code from the main branch.
Bonus point: tearing down the whole preview is just a matter of deleting this namespace. A single action on the Kubernetes API cleans up all preview resources!
To avoid domain collisions, we prepend each ingress host with the PR's branch name. For instance, if a staging application is publicly available under app.example.com and we're previewing the changes proposed on a branch named foo, those changes will be visible at foo-app.example.com. This is an intuitive shareable address that will respond for as long as the changes on the branch foo are being discussed.
Running WeStage
WeStage is operated like any other service at WeTransfer, ie. it gets deployed to dev and staging clusters for internal testing, and to the production cluster for all engineers to use. This means that for WeStage, a Kubernetes cluster is both the environment where the service runs and the target of the service's work (where previews are deployed).
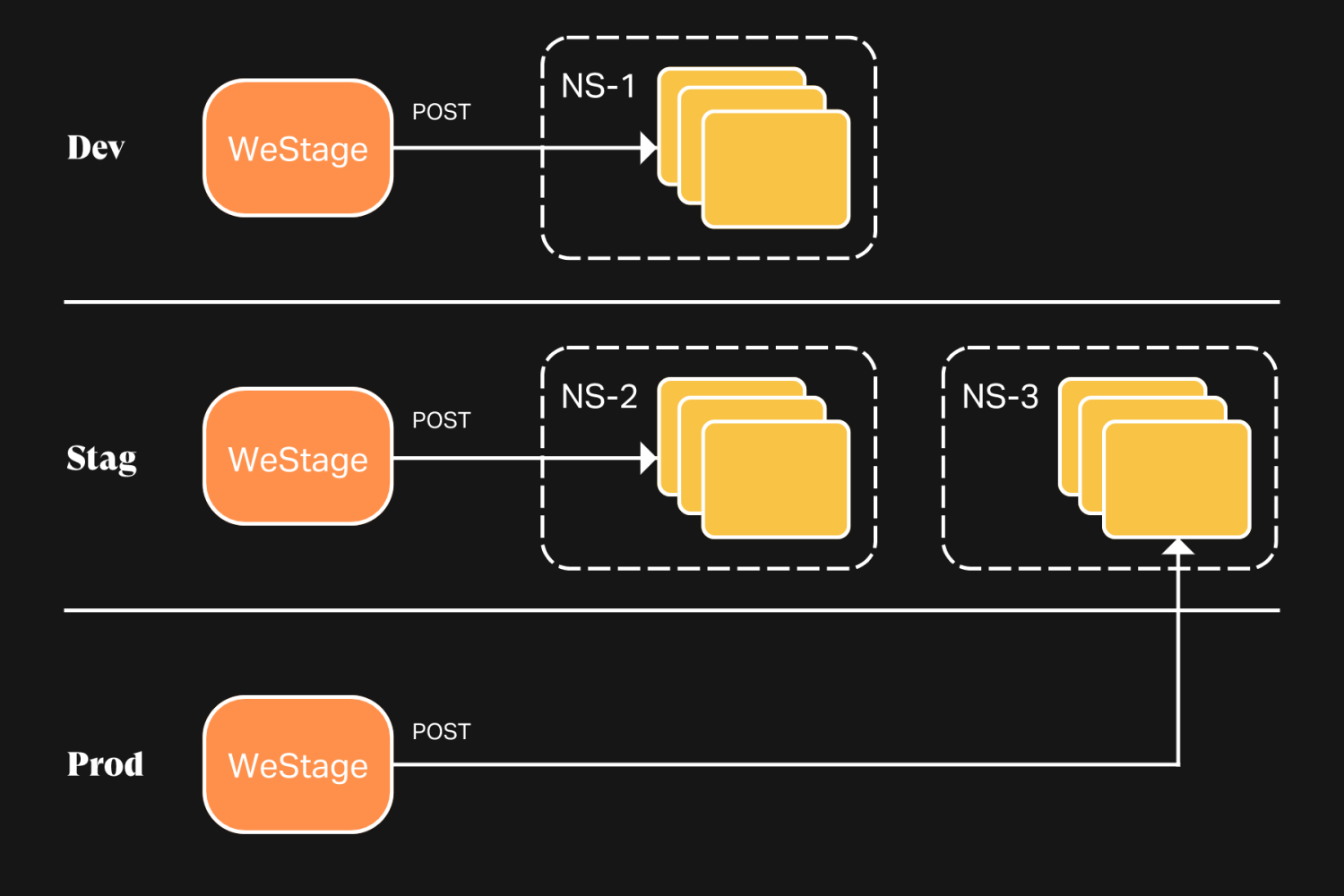
For the dev and staging instances of WeStage, we have a simplified model where the service's environment and its target are one and the same: these instances deploy previews through the Kubernetes API "next to them". For production WeStage, the service's environment is production, but its target is staging, meaning that the kubernetes client instantiated by the WeStage worker needs to be granted credentials for a kubernetes API different than the one that it is running next to. This is solved by creating a westage service account on the staging cluster, and storing its credentials and corresponding API endpoint with the secrets of the production instance of WeStage.
Dealing with Dependencies
The setup described above can deliver previews for many of the simpler services that we host. However, many services rely on external dependencies, and sharing those dependencies across all previews isn't an option: we need to provide them with isolated ephemeral dependencies. We currently support the two most common dependencies in WeTransfer services: MySQL databases and AWS SQS Queues.
For each of WeTransfer's services, WeStage stores configuration specifying their dependencies: when a preview application requires a dependency, WeStage worker renders Kubernetes manifests based on an official docker image and assigns them to the k8s namespace of the preview. It also injects env vars (eg WESTAGE_MYSQL_URL) pointing to this dependency in the pod specs of the preview. It's up to the service owners to populate a blank DB as they see fit: a common pattern is to add an initContainer that runs migrations and populates the DB when the deployment is known to run in a preview environment.
The other dependency pattern that WeStage supports is the reception of webhook callbacks. For example, some applications are integrated with Stripe: they call Stripe's API and receive callbacks from it (an application receives calls from Stripe when it is registered as an event listener), dynamically registering each preview instance isn't an option, because there's a limit of 20 slots for webhooks on Stripe's API, which would limit WeStage's capacity for simultaneous previews.
We've turned the problem on its head by developing a small proxy called WeHook that is registered as a single event listener on Stripe. WeHook regularly fetches a list of all running previews from WeStage and fans out the Stripe callbacks it receives to each of those preview instances. Each preview instance then determines if the callback corresponds to a Stripe operation initiated by itself.
Conclusion
Putting the user's experience at the center of a project was a novel approach for the team, and it proved very useful in clarifying our goals and priorities. Ultimately, we also believe that it set us up for success: WeStage has been embraced by both engineers and non-technical stakeholders, proving its value in a very short period both in terms of time-saving and infrastructure cost reduction.
On the technical side, delivering WeStage was... easier than we anticipated, which might sound anticlimactic. This has grown our appreciation for the components we're standing on: on the one hand, the Github API, but more critically the Kubernetes API. The latter provides clean and pertinent primitives, and it feels like we've barely scratched the surface in terms of what's possible. It is a robust foundation for the platform, and we're getting more and more value out of it as we extend its functionality and migrate workloads there.
To be continued...