
We all know how boring it is to sign a big pile of documents. Tax returns anyone? At WeTransfer we need to create signed URLs to files, but fortunately for us, we're not in the old days of Johannes Gutenberg anymore, as we do it automatically.
New inventions brings new problems, and we soon discovered that for transfers containing more than a couple of thousands of files, the process was really slow, causing annoying timeouts to our users.
The answer lies in the wise words of Kent Beck, who we respect deeply for pushing boundaries:
Make It Work, Make It Right, Make It Fast
What can we change in order to reduce the time required to sign these big transfers? Can we do better? Can we go faster?
The answer is: yes, we can go 45 times as fast!
Discovering the problem
When you download something from WeTransfer, we generate a bit of information called a waybill. A waybill gives instructions to our download server to serve you a single file – stored on S3 – proxying it while you are downloading it.
If you are downloading a transfer with multiple files, our download server is going to stream the contents of the file, and then generate a segment of a ZIP file for you to open later - we generate ZIPs on the fly this way. So if you have a transfer with a large number of files, the waybill will contain as many presigned S3 URLs as you have files in your download - sometimes reaching into tens of thousands of URLs in one waybill. The waybill needs to be generated immediately when you click "Download" in the UI.
And as we found: it adds up. Our research started with seeing this seemingly innocent message from our amazing support agents:

So one would click "Download", then wait, and then see their action time out without any sensible outcome. No good. We examined the report in a bit more detail, and found that the problem occurred on transfers with lots of files (a few thousand or more). Something was causing requests to time out and eventually annoy the user. Transfers of this type (with many many files in them) can be part of a thesis project for example, which can be critical to send when the deadline approaches.
We then started walking the chain of services which furnish the streaming download links to our users. First the main timeout came into view - that is our global timeout on all "foreground" HTTP calls on the main application. We set it as a very liberal 30 seconds of runtime - regardless of whether your underlying services are cooperative, we will abort the response generation procedure after that amount of time, primarily - to protect our infrastructure.
Then we have a number of calls into "satellite" services as we call them - the service which generates the actual download link is one of those satellite services. And we could look at the instrumentation for that service, and when we did it became apparent that this service took way more than 30 seconds to deliver a reply.
Contrary to what one might think, a web service is - by default - not designed for early cancellation. If you have a chain of services calling each other you will notice that even if you might kill the API request on one service, the service that is getting called will still complete the response generation and will still reply - even though the calling service has long "bailed out". So even if you do have good timeouts on the initial calling service, you will also need to have them in the services that service calls out to. In our case the main application would indeed time out after 30 seconds, but the satellite service would happily continue generating the download link and would reply "into the void" with that link.
By examining the calls on the satellite service we quickly narrowed the problem down to requests where we would be generating waybills for downloads containing thousands of files.
And so we had a few options ahead of us. We could increase the timeout on the main application – but this is very undesirable, if anything one would prefer to make that timeout shorter: the exact opposite. We could store our waybills for a much longer time and somehow reuse their fragments – apply some sophisticated caching strategy. But that would still not handle most of our "long tail" of requests as most of the waybills would be generated "afresh", as they are for transfers destined to just a couple of recipients. And: we could dive in and optimize. So that's what we did.
Where can we optimize?
In Appsignal, which we use for our performance monitoring, there is a possibility to include instrumentation spans. To understand the problem we added instrument do ... wrappers to the crucial parts of the download waybill generation process. For example, saving the waybill would be Appsignal.instrument('save_waybill_into_redis') do ... wrapper and so on. This gives you a great "waterfall view" of how long the various operations take. And once we did we were astonished to find out that generating presigned S3 URLs was what's costing us more than 95 to 97 percent of the wall clock time of the call. With that information it was obvious that even with the current 99-th percentile of transfers with large number of files our performance budget would not be covered if generating those URLs would take as long as it did.
And the code for doing that looks roughly like this:
file_keys_in_transfer.each do |file_key_on_s3|
waybill.add_file(bucket.object(file_key_on_s3).presigned_url(:get, expire_in: link_ttl)
endWe use AWS S3 to store our transfers, and we rely on the AWS SDK for Ruby to get signed urls for each S3 key (a file is "an object identified by a key" in AWS language).
The presigned URLs are a URL combined with an access grant. A presigned URL can only be used within a fixed time window, it gets issued for a specific object on S3 (for a specific file), and it gets issued on behalf of a specific AWS account. All of that information is cryptographically signed and included in the URL. These URLs are a great security mechanism, as they allow URLs to have limited validity as well as allow a credential (a user account) to be deactivated rapidly, expiring all of the URLs derived on behalf of that account. Switching to public URLs (and public-read access, as it's called in AWS language) would not work for us, as most of the data that we serve from S3 is private – it is only meant for the actual transfer recipient.
Signing a URL is a step by step process where a sequence of hash operations (HMAC operations) happens. Hashing can be somewhat expensive computationally.
Therefore we "homed in" on the S3 URL generation process, which - in the AWS SDK - is handled by the class called Aws::Sigv4::Signer. And to figure out what was going on it was time to bring out the big guns – ruby-prof. It was apparent that if we could "crack" the signing slowness we would be able to massively speed up our API call, and thus drive the download link generation back to the acceptable wall clock duration.
So we applied ruby-prof to our code where the URLs would be generated, and then we could take a look at the flamegraph:
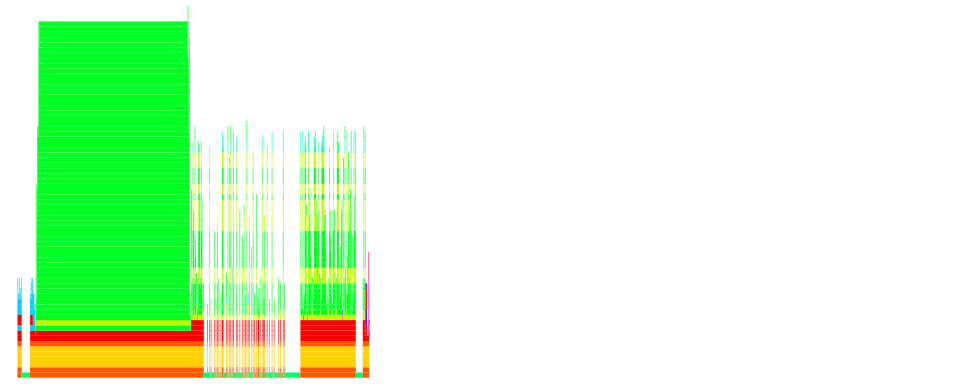
From that it becomes clear that a lot of time is spent in various "dark corners" of the AWS SDK. Looking at the flamegraph "from 10000 feet" we see two distinct "peaks". The first one has to do with credential discovery in the AWS SDK. That does take a little processing time but should amortize much better over the various calls: a possible optimization opportunity there.
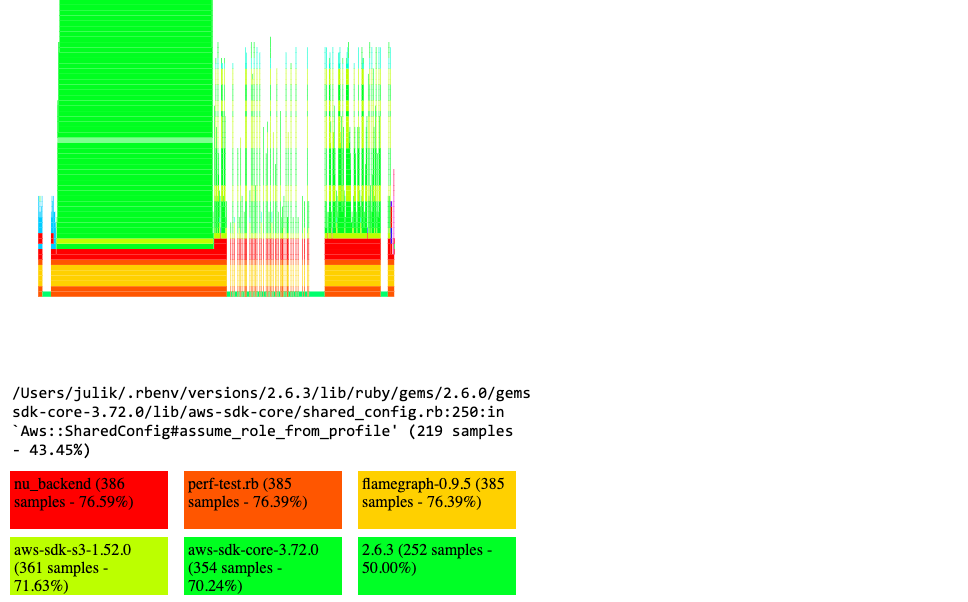
So there might be some room to optimize for that. The second "peak" has to do with the signing itself - and when we zoom into it we can see that there is a whole "pyramid" of handles which is responsible for normalizing, cleaning up and canonicalizing the signed URL components.
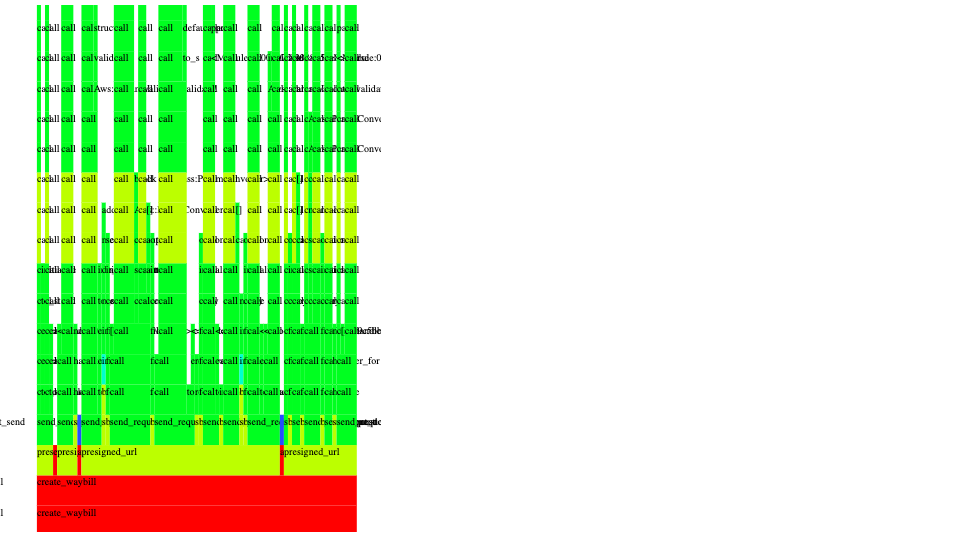
Even though computing an HMAC from the string-to-sign is, indeed, computationally costly it is by far not the biggest time spender here. Much more time is spent on discovering the IAM identity, discovering the bucket endpoint, and combining all of this in just-the-right-way.
Since there was a lot happenning in that code we thought: what if we copy the reference implementation and make it as dumb as possible first? This would allow us to try the simplest implementation at the start, and then re-add the bits of sophistication from the official SDK as we turn out to need them.
It was not directly scientific, but more of a bet – since the signing implementation is documented we should be able to try a clean-room implementation, and if we fail at it we will only have spent a day or two on it.
First Implementation
The process of URL signing in the SDK can be found in the Aws::Sigv4::Signer source on GitHub, and the implementation is described in the Signing AWS Requests with Signature Version 4 document. This makes the signing process transparent, but also allows developers to use custom signer implementations – maybe in other languages for which Amazon does not provide an SDK. This allows a few remarkable unofficial SDKs to exist - such as the one for the Crystal programming language - and is what made the Go SDK viable before it was officially adopted by AWS.
Admittedly, examining the Signer source code turned out to be much trickier than just reading the reference documentation - so we opted for the documentation instead. Our focus was to cut as much overhead as possible and be on the lookout for optimizations we could apply once our implementation would be working. We knew that we could "misuse" the fact that the URLs we generate were always from the same AWS credential (IAM role), and always for objects residing in the same few buckets.
The signing process is meticulous but straightforward, and for our first version we ported the official Python example to Ruby, "word for word". There's no black magic in there. We only needed URLs to sign, therefore we used the "Using GET with Authentication Information in the Query String (Python)" example.
Before going into the details, something important needs to be pointed out. While some of the components of the signing process require hexadecimal encoding, the signing key, used to generate the signature to be sent to AWS, requires a byte encoding – so the digests need to be passed around as a Ruby String object in Encoding::Binary. The code should not do this:
prefixed_key = "AWS4" + key
k_date = OpenSSL::HMAC.hexdigest("SHA256", key, data)
k_region = OpenSSL::HMAC.hexdigest(k_date, region)
k_service = OpenSSL::HMAC.hexdigest(k_region, service)
OpenSSL::HMAC.hexdigest(k_service, "aws4_request")Instead, it should do this:
prefixed_key = "AWS4" + key
k_date = OpenSSL::HMAC.digest("SHA256", key, data)
k_region = OpenSSL::HMAC.digest(k_date, region)
k_service = OpenSSL::HMAC.digest(k_region, service)
OpenSSL::HMAC.digest(k_service, "aws4_request")Notice the subtle difference between digest and hexdigest methods. This is where our habit of testing against actual AWS resources really helped (our download would fail, with a signature error)
First Results
First benchmarks were already incredibly promising. We went from ~11.956185 sec using the SDK to ~0.841381sec using our custom signer, for a stub/fake transfer with 10757 entries. For something that was basically "a reference implementation copy-pasted from the internet in a structured way" it was already a great win! But we knew we could go faster.
We would use a script like this to compare implementations:
require 'benchmark/ips'
require_relative 'lib/nu_backend'
require_relative 'spec/support/resource_allocator'
Benchmark.ips do |x|
x.config(:time => 5, :warmup => 2)
begin
aws_allocator = ResourceAllocator.new
bucket, bucket_name = aws_allocator.create_s3_bucket_and_name
client = Aws::S3::Client.new
resp = client.get_bucket_location(bucket: bucket_name)
bucket_region = resp.data.location_constraint
creds = client.config.credentials
signer_params = {
aws_region: bucket_region,
s3_bucket_name: bucket_name,
aws_credentials: creds,
expires_in: 60
}
we_signer_fast = WeSignerFast.new(**signer_params)
s3_signer = S3Signer_SDK.new(**signer_params)
x.report("WeSignerFast#presigned_get_url") do
we_signer_fast.presigned_get_url(object_key: 'dir/testobject')
end
x.report("S3Signer_SDK#presigned_get_url") do
s3_signer.presigned_get_url(object_key: 'dir/testobject')
end
ensure
aws_allocator.cleanup_all
end
x.compare!
endand the S3_Signer_SDK was our way to do S3 signing using the AWS SDK, so that the interfaces are the same:
class S3Signer_SDK
def initialize(aws_region:, s3_bucket_name:, aws_credentials: :AUTO, expires_in:)
# Credentials set to :AUTO because the AWS SDK will be able to
# automatically deduce them
@bucket = Aws::S3::Bucket.new(s3_bucket_name.to_s)
@expires_in = expires_in
# Region and credentials are autodetected by the AWS SDK anyway
end
def presigned_get_url(object_key:)
@bucket.object(object_key).presigned_url(:get, expires_in: @expires_in)
end
endResourceAllocator is our module we use in RSpec tests to generate temporary AWS resources - we test with real ones.
Obviously we were curious whether reusing a Signer object from the SDK would make a difference, but it turned out it didn't – or the difference was close to unnoticeable. It didn't matter whether one used Object#presigned_url or one of the Signer methods.
The URL escaping part
Interestingly enough, for us it didn't paint as if the greatest offender was the URL escaping part of the signing process but rather all the intermediate strings and hashes that one needs to generate. Maybe it was because we weren't using objects with keys containing characters needing escaping - or characters which need URL escaping at all. So in our code we were able to remove the URL escaping part completely – or rather, for our use case we don't need to use it. Our object keys are all URL-safe with just a few forward slashes for separation.
Apparently using a faster URL escaping module can boost performance even more - as evidenced by this bit of research but the gains we have received by skipping a lot of the processing already have gotten us way above the performance increase that we needed.
Pedal to the metal
Upon closer examination it turns out that quite a few elements required in the signing process do not change between calls, as long as the input parameters are the same. These are the strings identifying the service we are generating the URLs for ("S3"), the bucket endpoint and a whole number of headers we heed to mark as "signed". Since we always generate a bulk of URLs for the same S3 bucket, discovering this information (the bucket endpoint, the ARN and so on) for every URL is incredibly wasteful - it sometimes includes network calls even! We could retrieve this information once, at the start of the "signing session" (signing of a large number of similar URLs) - once. And then reuse that information for all the URLs in a batch.
For instance, the canonical query string created at step 4 of the "Using GET with Authentication Information in the Query String (Python)" example, is created with values that do not change while signing multiple URLs, so we cached them all. Including the expiry time, as we set it once at instantiation of our Signer object (cheat where appropriate, as they say).
When you sign a URL you sign it from a specific IAM identity or principal – you encode "who" signs the URL. This credential is, in better security setups like the one we have – temporary, but it is valid for some time and thus can be cached for that time. If we can fit our signing process within the lifetime of that credential – and compute that credential only once for our entire batch – we again can reuse that credential in the entire batch. So credential discovery can be performed once – even more time saved!
The signing key – the one which requires a sequence of HMAC operations to be performed – can be cached too, as long as the components it gets derived from do not change! It does use a datestamp, but the datestamp has some resolution to it, it can be a few seconds off as it accounts for clock drift between computers. The actual signing of the URL uses that derived key, and for a certain amount of time – when the credential is still valid and the datestamp used to derive the key is within tolerance – the key can be reused! So from doing 5 HMAC operations per URL (4 to derive the signing key and 1 for actually signing the URL) we can go to 1 + (4 / number_of_urls) per URL, as we amortize the key derivation over the entire batch. Even more time saved still!
For our second iteration we started caching non-changing elements as instance variables of our little hacky Signer object. You would instantiate it once, and give as many details about the URLs to be generated at initialization time. All the derived data for those would be lazily computed when you generate your first URL, and then reused for everything except for the object key (which becomes the path component of the generated presigned URL). Everything that has to do with credential and endpoint discovery was packaged into the for_bucket method which is a "targeted factory method" in Ruby parlance.
After these changes we ran the benchmarks again and deliver they did:
Warming up --------------------------------------
WeSigner#presigned_get_url
2.547k i/100ms
WeSignerFast#presigned_get_url
6.815k i/100ms
S3Signer_SDK#presigned_get_url
192.000 i/100ms
Calculating -------------------------------------
WeSigner#presigned_get_url
29.404k (± 6.0%) i/s - 147.726k in 5.044185s
WeSignerFast#presigned_get_url
66.074k (±17.3%) i/s - 313.490k in 5.091095s
S3Signer_SDK#presigned_get_url
1.607k (±24.4%) i/s - 7.488k in 5.131687s
Comparison:
WeSignerFast#presigned_get_url: 66074.4 i/s
WeSigner#presigned_get_url: 29404.3 i/s - 2.25x slower
S3Signer_SDK#presigned_get_url: 1607.3 i/s - 41.11x slowerOur hacky WeSigner turned out to be more than ~40 times faster than the SDK version, reducing timeout risks to negligible. It was ready to go to production 🚀 We have tested it exhaustively and were extremely pleased with the results.
Not only did we manage to surgically optimize a hot path with great results, but more importantly: it again became apparent that it was not the Ruby virtual machine "being slow because Ruby is slow". Rather it was because the actual software we were using - the official Signer module - was optimized out of the box for a different usage pattern than ours - for maximum flexibility and plug-and-play when signing any URL, from any bucket, using one and the same object in memory. The engineers working on the official SDK gem simply made different tradeoffs than we did. It is not something bad or regrettable but rather the reality of software - we all optimize for what matters to us, or – for what matters for most of our users and customers.
The gem
Thrilled by the idea that our signer was being used by "half of the population of the city of Utrecht (cit.)", we decided to take a step further and open source it.
The wt_s3_signer Ruby gem is available on GitHub, ready to be used and hoping to improve the life of your users. If you find that the license we use is problematic, you should give Jonathan's faster_s3_url a try - it is not as fast as wt_s3_signer (Jonathan, just like the original SDK authors, has made different tradeoffs - and that's perfectly OK), but it has the MIT license.
Special thanks to Jonathan Rochkind who stimulated us to finally share this post by publishing his own research into the matter.
